Text-to-Image AI (Ep.1)

เทคโนโลยี Gen AI (Generative AI) สร้างภาพจากข้อความ (Text-to-Image AI) เป็นนวัตกรรมล่าสุดในวงการปัญญาประดิษฐ์ ที่กำลังเปลี่ยนแปลงวิธีที่เราสร้างและจินตนาการภาพ เทคโนโลยีนี้ใช้ Advanced AI Model ที่สามารถแปลงคำอธิบายจากข้อความให้กลายเป็นภาพที่สมจริงและสร้างสรรค์
หลักการทำงานของ AI ประเภทนี้คือการรับคำอธิบายเป็นข้อความจากผู้ใช้ (หรือ Prompt) จากนั้นจึงประมวลผลและสร้างภาพที่ตรงกับคำอธิบายนั้น โดยอาศัยการเรียนรู้จากฐานข้อมูลขนาดใหญ่ที่ประกอบด้วยคู่ของภาพและข้อความบรรยาย ด้วยความสามารถนี้ทำให้ผู้ใช้สามารถสร้างภาพที่ซับซ้อนและหลากหลายได้เพียงแค่พิมพ์คำอธิบาย
ตัวอย่างของ AI สร้างภาพจากข้อความที่เป็นที่รู้จักกันดี ได้แก่ DALL-E ของ OpenAI, Midjourney, และ Stable Diffusion ซึ่งแต่ละระบบมีจุดเด่นและความสามารถเฉพาะตัว
เทคโนโลยีนี้กำลังส่งผลกระทบอย่างมากต่อหลายอุตสาหกรรม เช่น Graphic design, Content creation, Advertising, Entertainment โดยช่วยลดเวลาและต้นทุนในการสร้างภาพ ทั้งยังเปิดโอกาสให้ผู้ที่ไม่มีทักษะด้านศิลปะสามารถสร้างสรรค์ภาพตามจินตนาการของตนได้
อย่างไรก็ตาม การใช้ AI สร้างภาพจากข้อความก็มาพร้อมกับความท้าทายและข้อควรพิจารณาด้านจริยธรรม เช่น ประเด็นเรื่องลิขสิทธิ์ ความเป็นส่วนตัว และความเป็นไปได้ในการสร้างข้อมูลเท็จหรือภาพที่อาจก่อให้เกิดความเข้าใจผิด
ในอนาคต คาดว่าเทคโนโลยีนี้จะพัฒนาให้มีความแม่นยำและยืดหยุ่นมากขึ้น ซึ่งอาจนำไปสู่การเปลี่ยนแปลงครั้งใหญ่ สำหรับวิธีที่เราสร้างและใช้งานภาพในชีวิตประจำวันและในวงการธุรกิจ
ตัวอย่าง Application Text-to-Image AI ที่ชื่อว่า Leonardo.ai
1) ติดตั้ง Application หรือ เข้าใช้งานผ่าน Website Leonardo.ai
2) สร้าง Account ซึ่งจะมี Free coin ให้ 150 coins (ข้อมูลวันที่ 17 ก.ย. 67) ในการสร้างแต่ละรูป ต้องใช้ Coins (จำนวนจะแตกต่างกันไปขึ้นกับ Engine ที่เลือกใช้ และ จำนวนภาพ)
3) เลือกที่ Image generation
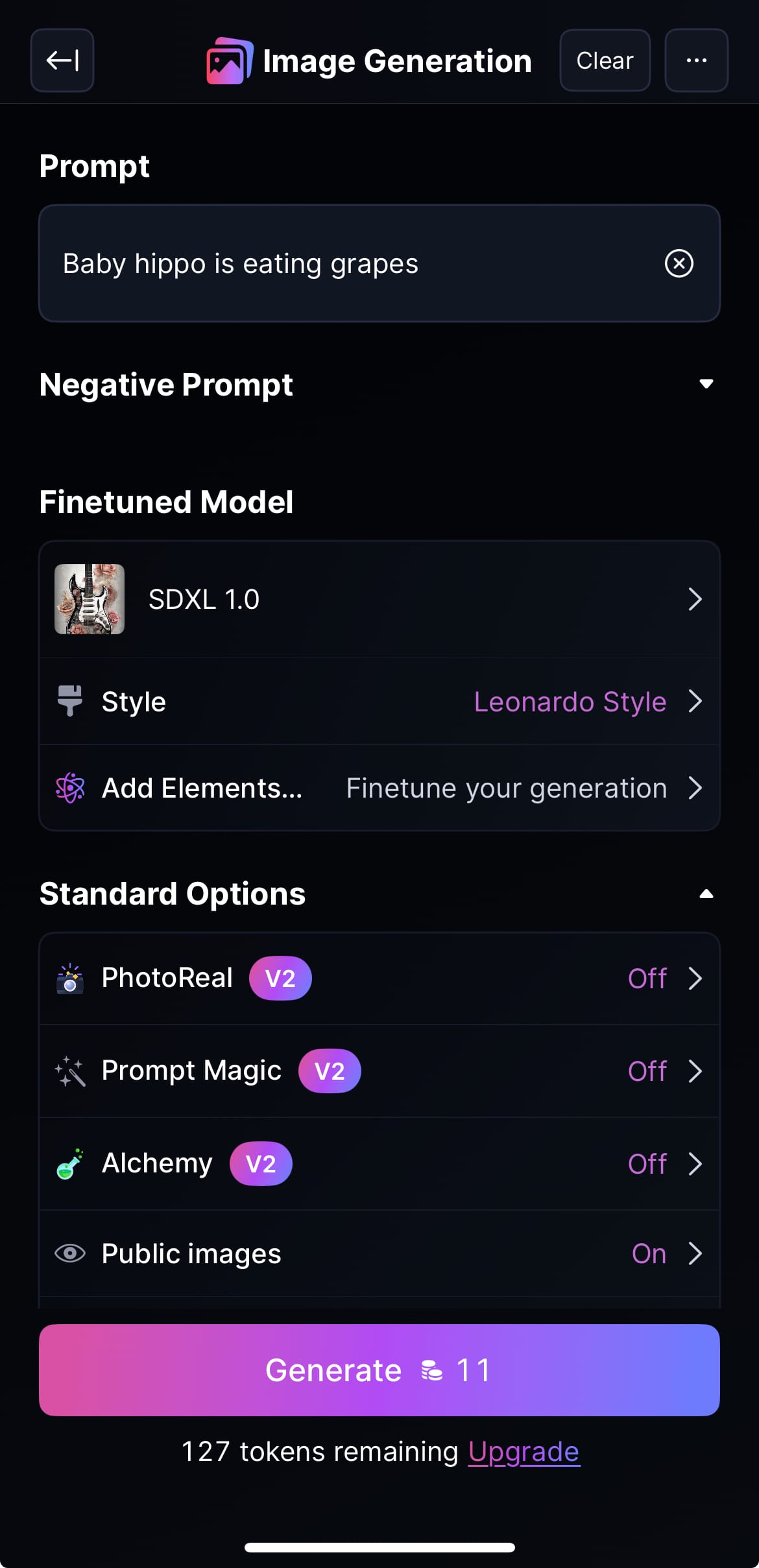
4) ใส่ Prompt ในที่นี้ คือ “Baby hippo is eating grapes.” โดยเลือก Engine ที่ใช้ คือ SDXL 1.0 ซึ่งจะใช้จำนวน 11 Coins (เพื่อ Generate)
5) รูปภาพที่ได้

Blog นี้ เขียนร่วมกับ Claude.ai โดยใช้ Prompt
What is the text-to-image AI? Please give an introduction.


