SVM คือ อะไร

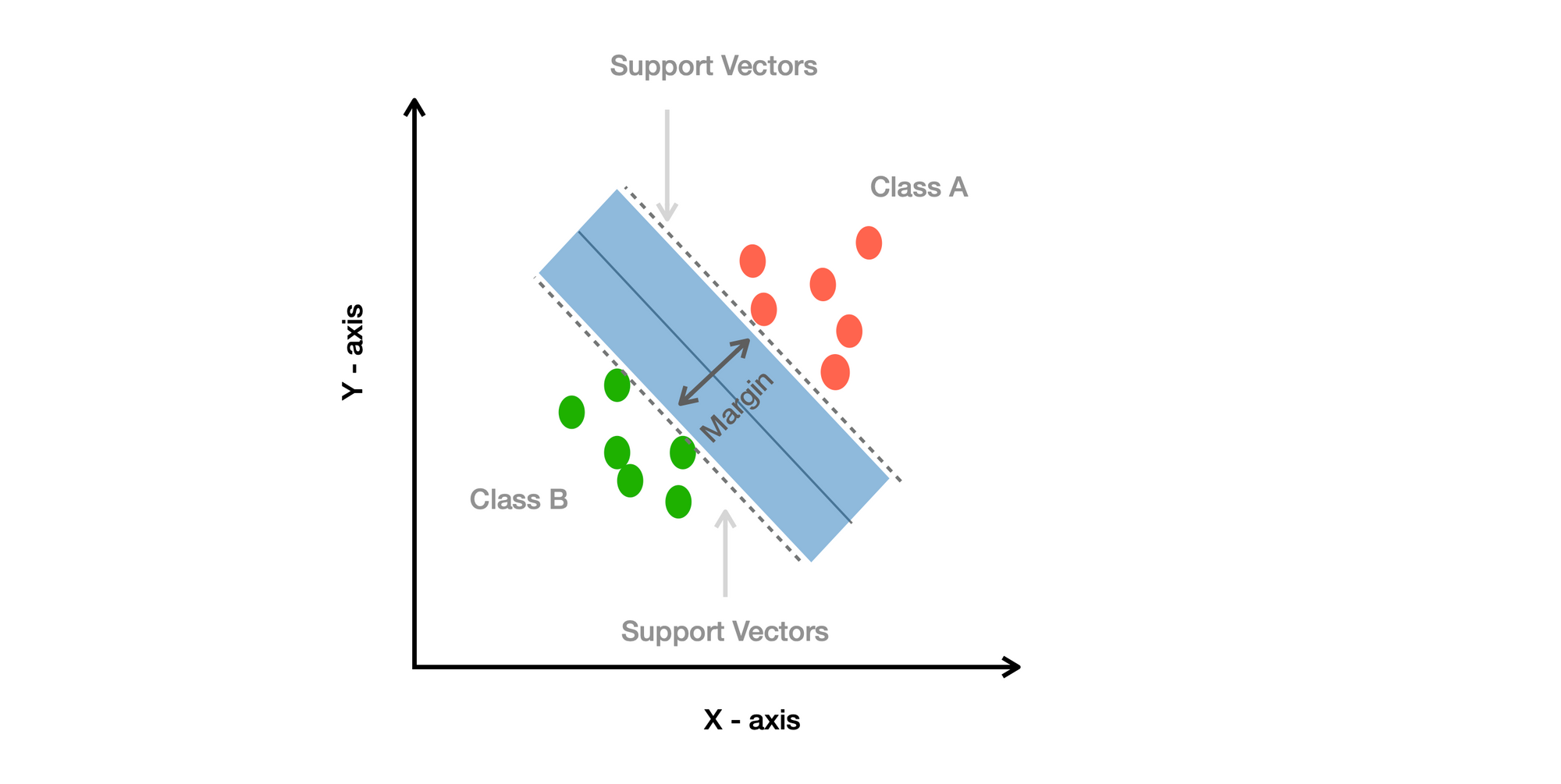
SVM ย่อจาก Support Vector Machine เป็น Machine Learning Algorithm ประเภท Supervised Learning มีเป้าหมาย คือ หา Hyperplane ใน N-dimensional Space โดยที่ N คือ จำนวน Features เพื่อใช้ในการ Classify Data Points
ทำไมถึงใช้ SVM
- มีประสิทธิภาพใน High-dimensional Space
- ยังคงมีประสิทธิภาพ เมื่อจำนวนของ Dimensions มากกว่า จำนวนของ Sample
- ใช้ Subset ของ Training Points (Support Vectors) ทำให้ใช้ Memory ได้อย่างมีประสิทธิภาพ
- Kernel Functions ที่แตกต่างกัน สามารถใช้ในการกำหนด Decision Function ได้
🟢 ข้อดี
- จัดการกับ Non-Linear ได้ โดยใช้เทคนิคของ Kernel
- การ Maximized Margin ทำให้เกิดความทนทานที่ดี (Robustness)
- สามารถควบคุม Overfitting โดยใช้เทคนิค Soft Margins
🔴 ข้อเสีย
- ไม่เหมาะกับ Dataset ขนาดใหญ่ เนื่องจากใช้เวลาใน Train ที่นาน
- ประสิทธิภาพจะขึ้นกับการเลือก Kernel
- ต้องมีการทำ Feature Scaling ก่อน เพื่อให้ได้ Accuracy ที่ดี
Hyper-parameters ใน SVM
- C หรือ Regularization parameter กรณีค่า C น้อย จะหมายถึง การมี Margin ที่กว้าง ซึ่งอาจส่งผลให้มีการละเมิดเข้ามาใน Margin มากขึ้น กรณีค่า C สูง จะหมายถึง การมี Margin ที่แคบ มีเป้าหมายใน Classify Training Data ให้ถูกมากที่สุด โดยให้ Model มีอิสระในการเลือก Samples เข้ามามากกว่า ในการสร้าง Support Vectors
- Kernel คือ ประเภทของ Kernel เช่น ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’
- Degree คือ Degree ของ Polynomial Kernel Function (‘poly’) ในกรณี Kernels ประเภทอื่นๆ ไม่ต้องพิจารณาค่านี้
- Gamma คือ ค่า Kernel Coefficient ค่า Default คือ ‘scale’ ซึ่งจะถูกคำนวณจาก Data Inputs หากเลือก ‘auto’ จะใช้ 1/n_features
ตัวอย่าง Python Code 👨🏻💻
# Import libraries
from sklearn import datasets
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import confusion_matrix
# Load the dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Split train & test data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# SVM
clf = SVC()
# Define values for hyperparamters
params = {'C':[0.1, 1, 10], 'kernel':['linear','rbf'],'gamma': ['scale','auto']}
# Grid search for obtaining best parameters
grid_search = GridSearchCV(clf, params, cv=5)
grid_search.fit(X_train, y_train)
print (grid_search.best_params_)
# Train & predict by using the best parameters
clf = SVC(**grid_search.best_params_)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
# Print out confusion matrix
confusion_matrix(y_test, y_pred)******
อ่านเพิ่มเติม Pros & Cons ของ Machine Learning Algorithms ที่นิยมใช้
******
ข้อมูลอ้างอิง - Analytics Vidhya