RFM Model โดยใช้ Python

RFM ย่อจาก Recency, Frequency, Monetary ใช้เพื่อแบ่ง Segment ลูกค้า ถือเป็น Behavioral Segmentation มี 3 Features ที่สำคัญ คือ
- Recency - จำนวนวัน ตั้งแต่การซื้อครั้งสุดท้าย
- Frequency - จำนวน Transactions ในช่วงเวลาที่กำหนด
- Monetary - จำนวนเงินที่ใช้ ในช่วงเวลาที่กำหนด
สามารถทำการ Group (Aggregate) Features เหล่านี้โดย
- Percentiles หรือ Quartiles
- Pareto Rule - 80/20
- มุมมองทางธุรกิจ

ลงมือทำ
- ในที่นี้ จะใช้ E-Commerce Dataset จาก https://www.kaggle.com/fabiendaniel/customer-segmentation
- เรียกใช้ Libraries ที่จำเป็น จากนั้น Read Dataset และ แปลง Column “InvoiceDate” ให้อยู่ในรูปแบบ DateTime
# Import libraries
import pandas as pd
from datetime import timedelta
import matplotlib.pyplot as plt
import seaborn as sns
import squarify
# Read dataset
online = pd.read_csv('../data.csv', encoding = "ISO-8859-1")
# Convert InvoiceDate from object into datetime
online['InvoiceDate'] = pd.to_datetime(online['InvoiceDate'])- ขั้นแรก ต้องทำการจัดเรียงลูกค้าตาม ค่า Recency, Frequency, Monetary
- ทำการคำนวณ Total Sum = Quantity x Unit Price
- ในการคำนวณ Recency จะใช้ ค่าวันสุดท้าย + 1 ของ Invoice Date ลบ กับ วันที่ลูกค้าซื้อครั้งสุดท้าย
- จากนั้น ทำการ Group by “Customer ID” และ เก็บไว้ใน data_process
# Create TotalSum column
online['TotalSum'] = online['Quantity'] * online['UnitPrice']
# Create snapshot date
snapshot_date = online['InvoiceDate'].max() + timedelta(days=1)
print(snapshot_date)
# Group by CustomerID
data_process = online.groupby(['CustomerID']).agg({
'InvoiceDate': lambda x: (snapshot_date - x.max()).days,
'InvoiceNo': 'count',
'TotalSum': 'sum'})
# Change column name
data_process.rename(columns={'InvoiceDate': 'Recency',
'InvoiceNo': 'Frequency',
'TotalSum': 'MonetaryValue'}, inplace=True)
# Print top 5 rows & shape
print(data_process.head())
print('{:,} rows; {:,} columns'
.format(data_process.shape[0], data_process.shape[1]))- ดูผลลัพธ์ที่ได้ มีลูกค้า 4,372 คน แสดงผลด้วยค่า Recency, Frequency, Monetary
Output:
CustomerID Recency Frequency MonetaryValue
12346.0 326 2 0.00
12347.0 2 182 4310.00
12348.0 75 31 1797.24
12349.0 19 73 1757.55
12350.0 310 17 334.40
4,372 rows; 3 columns
- แสดงการ Plot Distribution ของ RFM
plt.figure(figsize=(12,10))
plt.subplot(3, 1, 1); sns.distplot(data_process['Recency'])
plt.subplot(3, 1, 2); sns.distplot(data_process['Frequency'])
plt.subplot(3, 1, 3); sns.distplot(data_process['MonetaryValue'])
plt.show()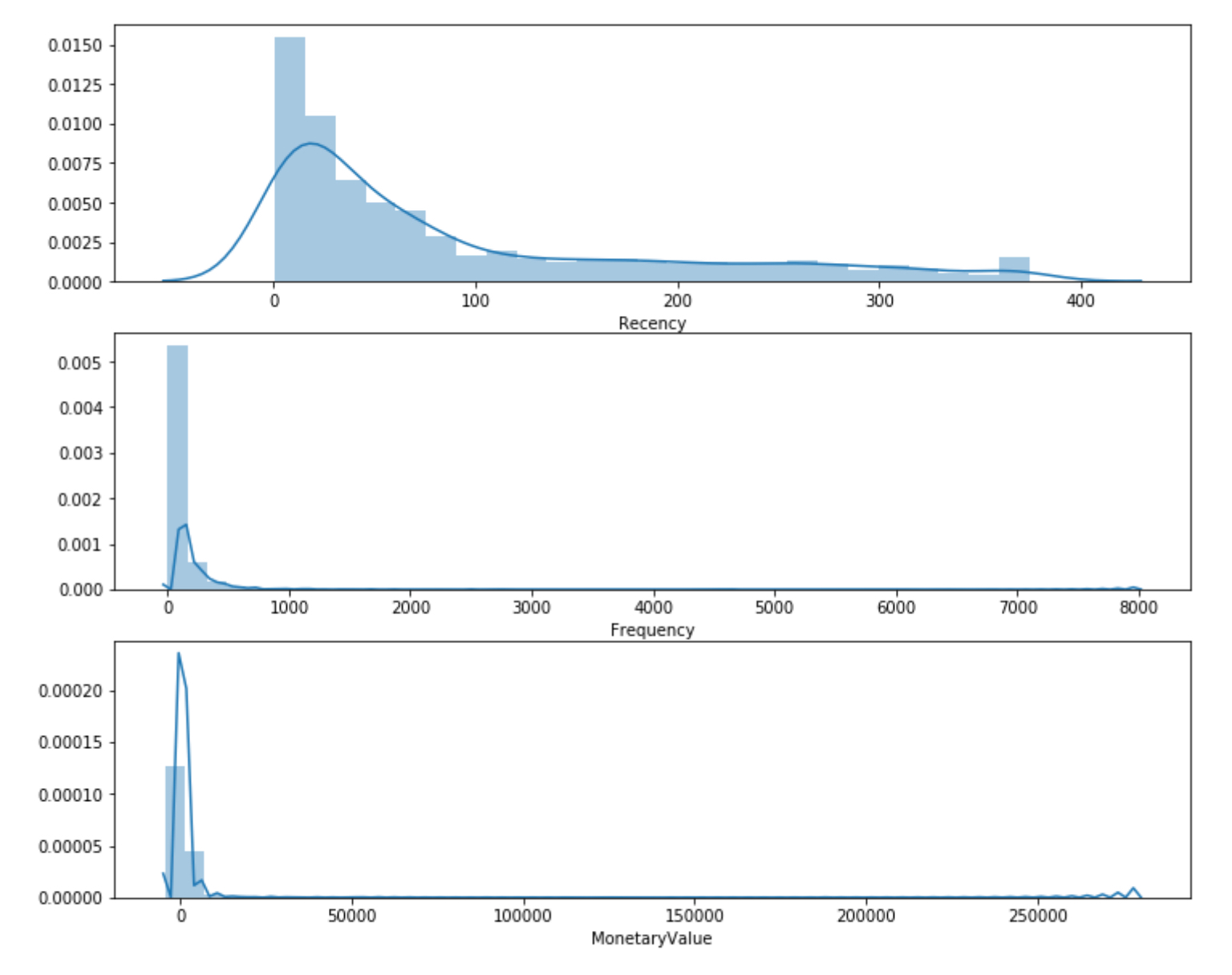
- จากการ Plot Distribution ทำให้รู้ว่า ข้อมูลมีการ Skewed ไปมากเพียงใด ในขั้นต่อไปเราจะจัดกลุ่มข้อมูลนี้ โดยใช้ Quartiles
- อย่างไรก็ตาม หากใช้ Algorithm อย่างเช่น K-Means ต้องแน่ใจว่าข้อมูลถูก Scaled ให้อยู่ที่ Center (พิจารณา Mean, Standard Deviation)
- ทำการให้คะแนน โดยแบ่งเป็น 4 กลุ่ม R, F, M โดย R ที่มีค่าน้อยจะได้คะแนนสูง (เพิ่งซื้อไม่นาน)
# Create labels for R, F, M
r_labels = range(4, 0, -1)
f_labels = range(1, 5)
m_labels = range(1, 5)
# Assign these labels to 4 equal percentile groups
r_groups = pd.qcut(data_process['Recency'], q=4, labels=r_labels)
f_groups = pd.qcut(data_process['Frequency'], q=4, labels=f_labels)
m_groups = pd.qcut(data_process['MonetaryValue'], q=4, labels=m_labels)
# Create new columns R, F, M
data_process = data_process.assign(R = r_groups.values,
F = f_groups.values,
M = m_groups.values)
data_process.head()
# Create RFM dataframe
rfm = data_process
rfm.head()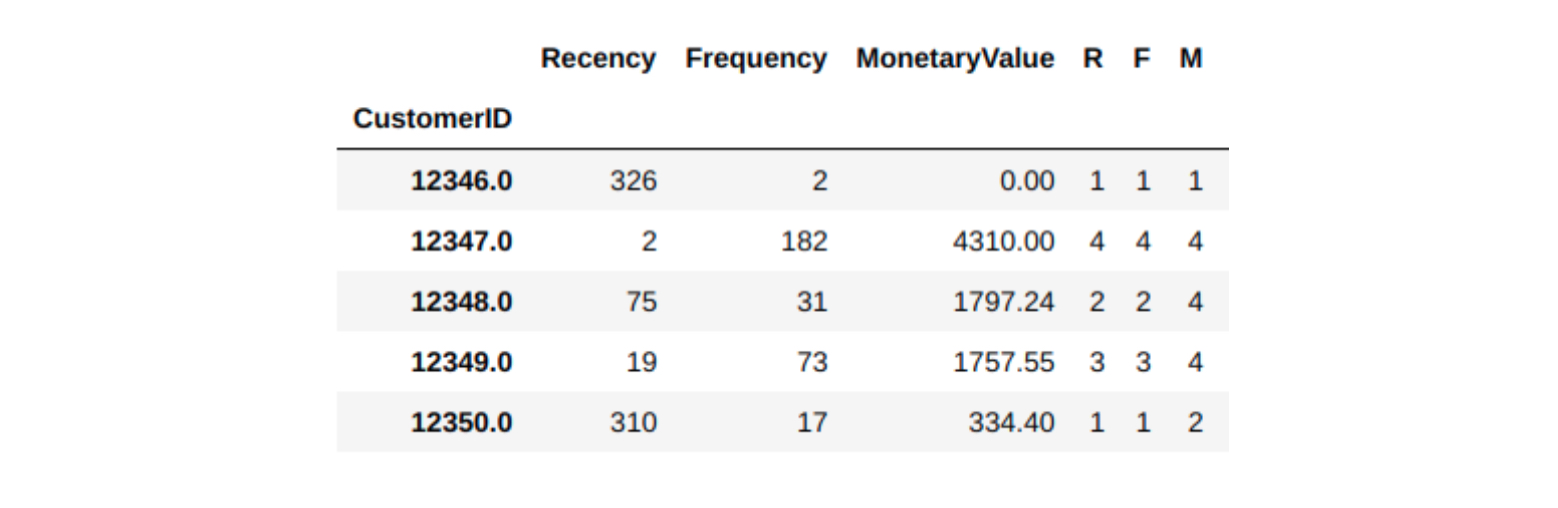
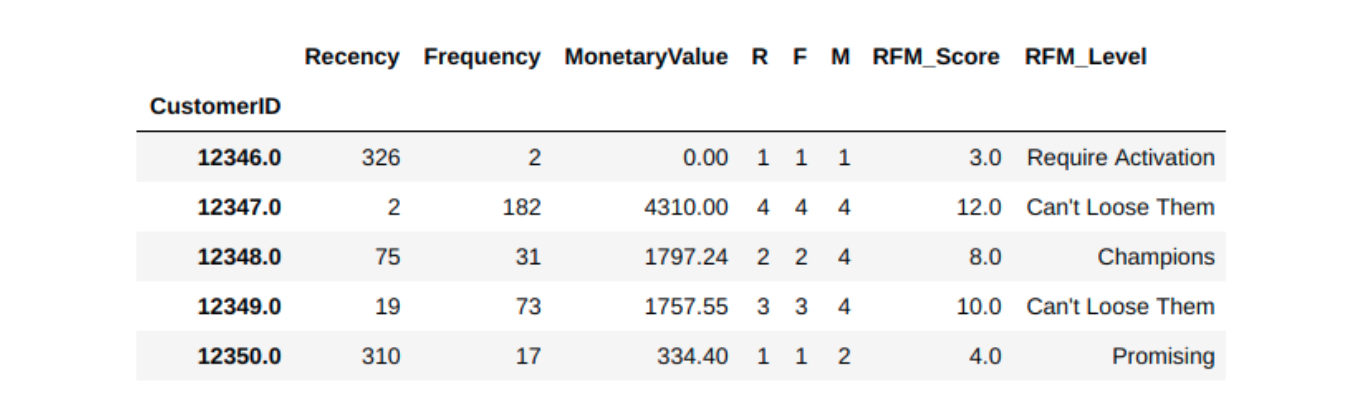
- การหาผลรวมของคะแนน เป็นวิธีการที่ตรงไปตรงมาอันหนึ่ง โดยรวมให้เป็นคะแนนเดียว และ กำหนด RFM Levels ในแต่ละช่วงคะแนน
# Calculate RFM_Score
rfm['RFM_Score'] = rfm[['R','F','M']].sum(axis=1)
print(rfm['RFM_Score'].head())Output:
CustomerID
12346.0 3.0
12347.0 12.0
12348.0 8.0
12349.0 10.0
12350.0 4.0
Name: RFM_Score, dtype: float64
- สามารถกำหนดได้ว่า แต่ละช่วงคะแนน จะให้ชื่อ Segments ว่าอะไร อาจให้ผู้เชี่ยวชาญในธุรกิจช่วยแนะนำ ในที่นี้ จะแสดงตัวอย่างแบบหนึ่ง
# Define RFM level
def rfm_level(df):
if df['RFM_Score'] >= 9:
return 'Can\'t Loose Them'
elif ((df['RFM_Score'] >= 8) and (df['RFM_Score'] < 9)):
return 'Champions'
elif ((df['RFM_Score'] >= 7) and (df['RFM_Score'] < 8)):
return 'Loyal'
elif ((df['RFM_Score'] >= 6) and (df['RFM_Score'] < 7)):
return 'Potential'
elif ((df['RFM_Score'] >= 5) and (df['RFM_Score'] < 6)):
return 'Promising'
elif ((df['RFM_Score'] >= 4) and (df['RFM_Score'] < 5)):
return 'Needs Attention'
else:
return 'Require Activation'
# Create a new variable RFM_Level
rfm['RFM_Level'] = rfm.apply(rfm_level, axis=1)
# Print the top 5 rows
rfm.head()
- ทำการหาค่า Mean และ Count เพื่อวิเคราะห์จำนวนลูกค้าแต่ละ Segment
# Calculate average values for each RFM_Level, and return a size of each segment
rfm_level_agg = rfm.groupby('RFM_Level').agg({
'Recency': 'mean',
'Frequency': 'mean',
'MonetaryValue': ['mean', 'count']
}).round(1)
# Pring the aggregate data
print(rfm_level_agg)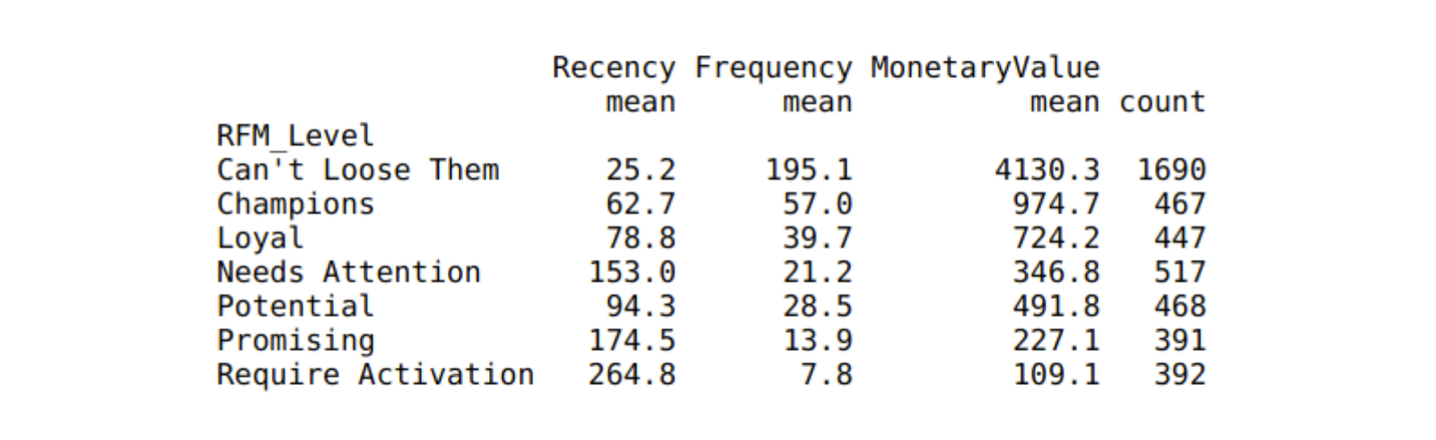
- จากที่นี่ เราจะเห็นได้ว่าลูกค้าส่วนใหญ่ (~ 60%) ของเราอยู่ในระดับ RFM สูงสุด ร้านค้าจะต้องพยายามรักษาความภักดีนี้ไว้ แต่อีก 40% ที่เหลือ อาจจะต้องมีการกระตุ้นบ้าง
- Potential - มีศักยภาพสูงในการเข้าสู่กลุ่มลูกค้า Loyal อาจลองแจกของสมนาคุณในการซื้อครั้งต่อไป เพื่อแสดงว่าเราให้คุณค่ากับพวกเขา
- Promising - มีแนวโน้มดี ทั้งปริมาณและมูลค่าของการซื้อ แต่เป็นเวลานานแล้วซื้อครั้งสุดท้ายจากเรา อาจ Target ด้วย Items ที่อยากได้ และ เสนอส่วนลดให้ในเวลาจำกัด
- Need Attention - ทำการซื้อครั้งแรก แต่ยังไม่มีการซื้ออีกเลย เป็นประสบการณ์ที่ไม่ดีของลูกค้าหรือไม่ ? หรือความเหมาะสมของผลิตภัณฑ์? อาจสร้างการรับรู้ถึง Brands ให้มากขึ้น
- Required Activation - กลุ่มที่แย่ที่สุด อาจใช้ผลิตภัณฑ์ของคู่แข่งอยู่ จะต้องใช้กลยุทธ์ที่แตกต่างออกไปเพื่อดึงกลับมา
- ทำการแสดงผล โดยใช้ Squarify Library
# Change column name
rfm_level_agg.columns = rfm_level_agg.columns.droplevel()
rfm_level_agg.columns =['RecencyMean','FrequencyMean','MonetaryMean',
'Count']
# Plot using Squarify
fig = plt.gcf()
ax = fig.add_subplot()
fig.set_size_inches(16, 9)
squarify.plot(sizes=rfm_level_agg['Count'],
label=['Can\'t Loose Them',
'Champions',
'Loyal',
'Needs Attention',
'Potential',
'Promising',
'Require Activation'], alpha=.6 )
plt.title("RFM Segments",fontsize=18,fontweight="bold")
plt.axis('off')
plt.show()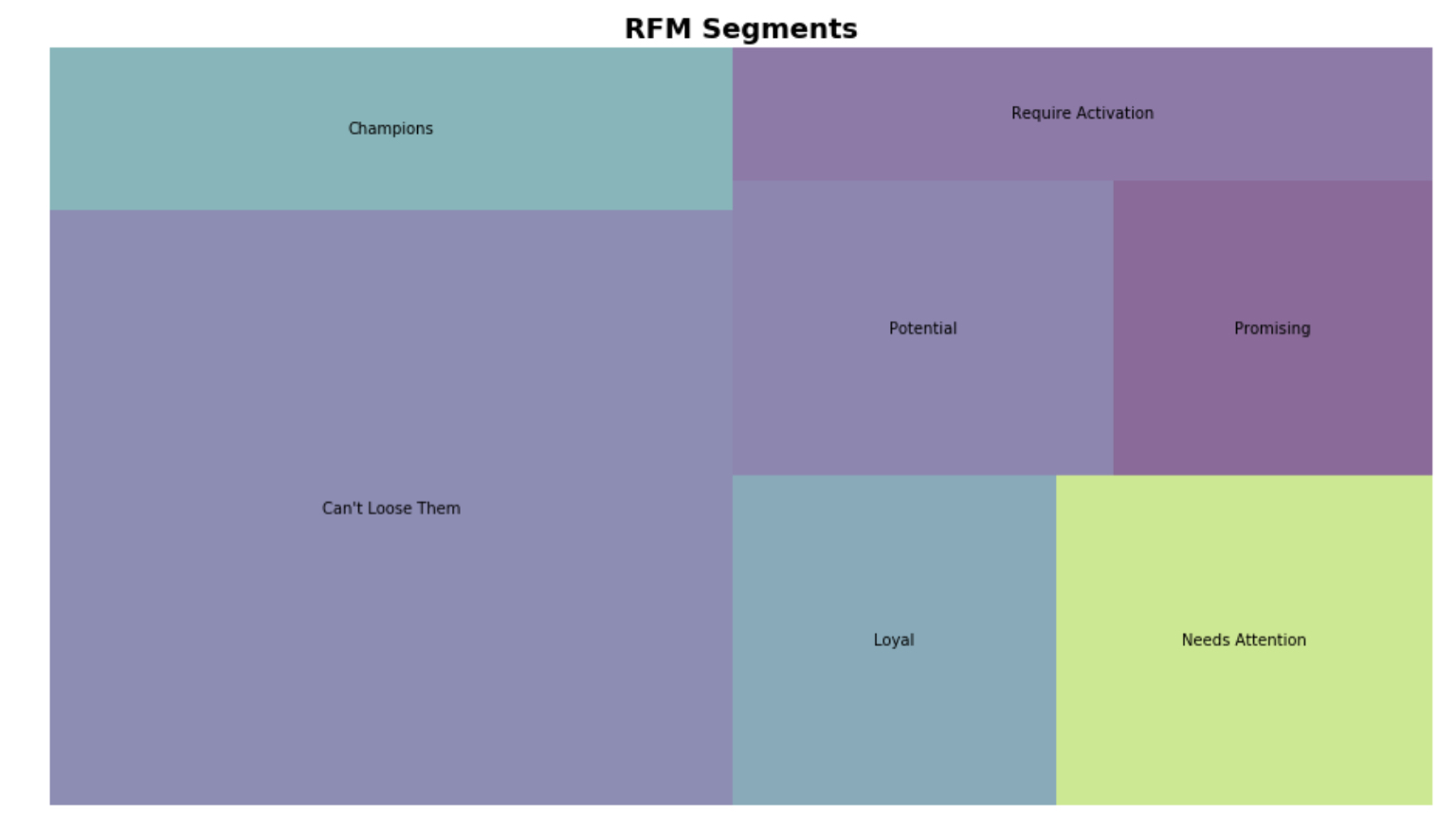
Tips (by Admin)
- การสร้าง RFM Model จำเป็นต้องกำหนดช่วงเวลา เพื่อไม่ให้เกิด Bias สำหรับลูกค้าใหม่หรือเก่า
- ในตัวอย่างแสดงการคำนวณ Score โดยใช้ Quartiles อาจใช้วิธีการอื่น เช่น Percentiles
- ในตัวอย่างให้ Weight ของ R,F,M เท่าๆ กัน (ไม่มีการกำหนด Weight) หากธุรกิจสนใจในเรื่องใดเรื่องหนึ่งมากกว่า เช่น F (Frequency) อาจพิจารณาให้ Weight ที่มากกว่าได้
******
ข้อมูลอ้างอิง - https://towardsdatascience.com/recency-frequency-monetary-model-with-python-and-how-sephora-uses-it-to-optimize-their-google-d6a0707c5f17


