Pros & Cons ของ Machine Learning Algorithms ที่นิยมใช้

ใน Blog นี้ จะพูดถึง Pros (ข้อดี) และ Cons (ข้อเสีย) ของ Machine Learning Algorithms ต่างๆ ที่นิยมนำมาใช้งาน
Linear Regression
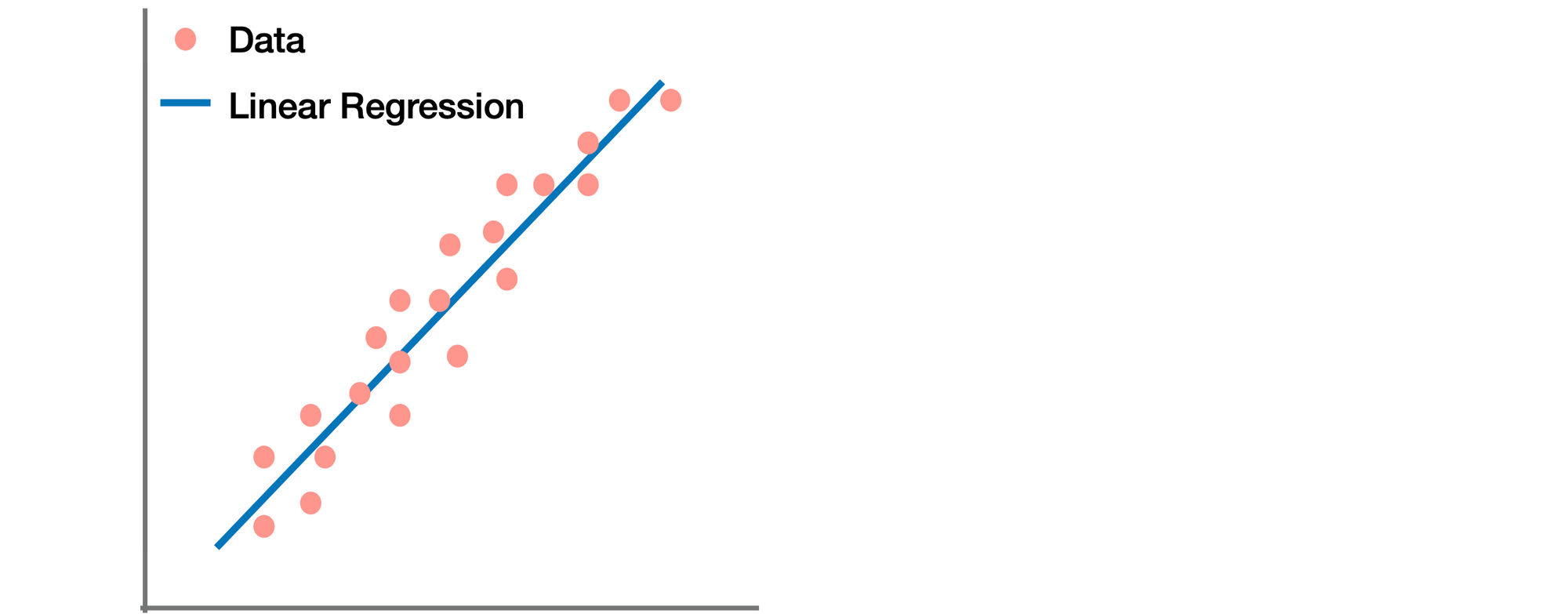
🟢 ข้อดี
- ง่ายในการ Implement และ มีประสิทธิภาพในการ Train
- สามารลด Overfit ได้ โดยใช้ Regularization
- ใช้งานได้ดี เมื่อ Dataset มีความสัมพันธ์แบบ Linear
🔴 ข้อเสีย
- สมมติฐาน คือ Features เป็นอิสระจากกัน ซึ่งพบในยากชีวิตจริง
- ไวต่อ Noise และ เกิด Overfitting ได้
- ไวต่อ Outliers
Logistic Regression
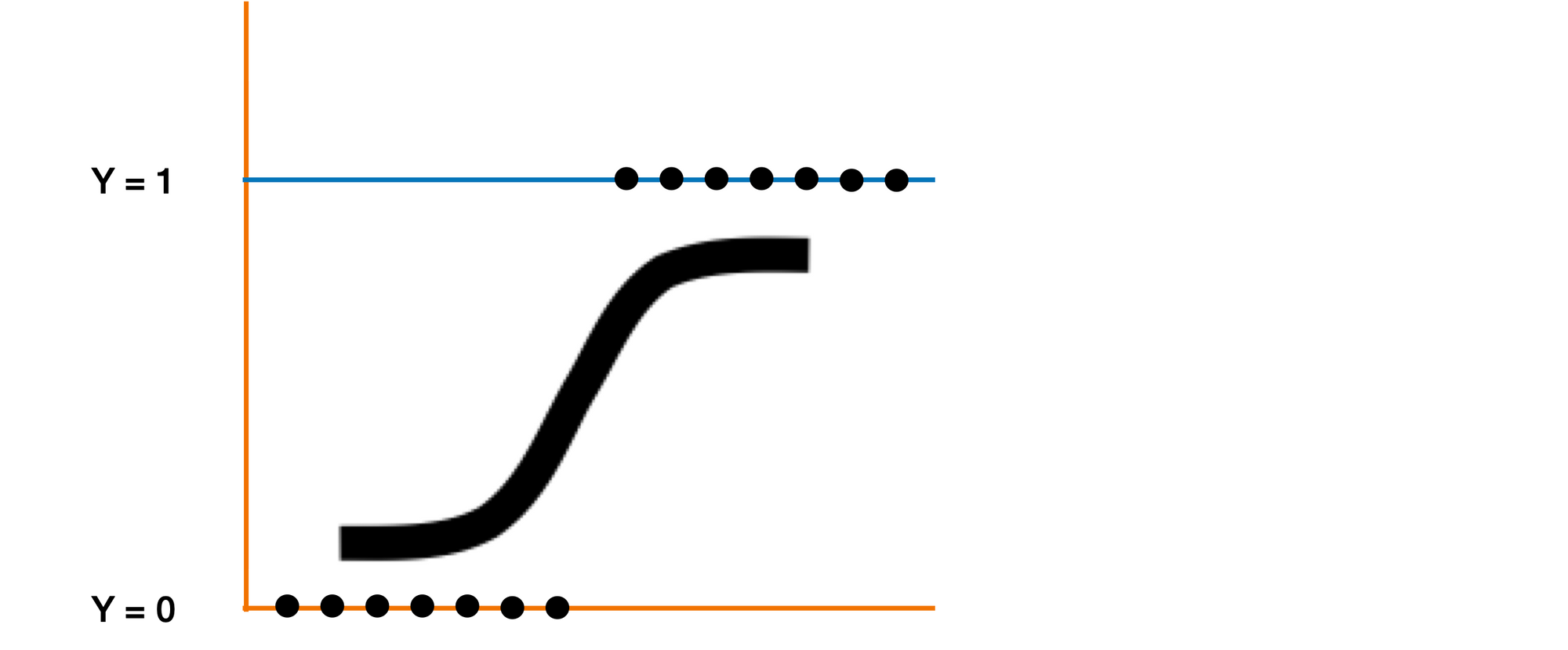
🟢 ข้อดี
- แนวโน้มที่จะเกิด Overfit น้อย แต่เป็นไปได้กรณี High Dimensional Datasets
- ใช้งานได้ดี เมื่อ Dataset มีความสัมพันธ์แบบ Linear
- ง่ายในการ Implement และ มีประสิทธิภาพในการ Train
🔴 ข้อเสีย
- ไม่ควรใช้ เมื่อจำนวน Sample น้อยกว่า จำนวน Features
- สมมติฐานที่เป็น Linear พบได้ยากใช้ชีวิตจริง
- สามารถใช้ในการทำนาย Discrete Function
Support Vector Machine (SVM)
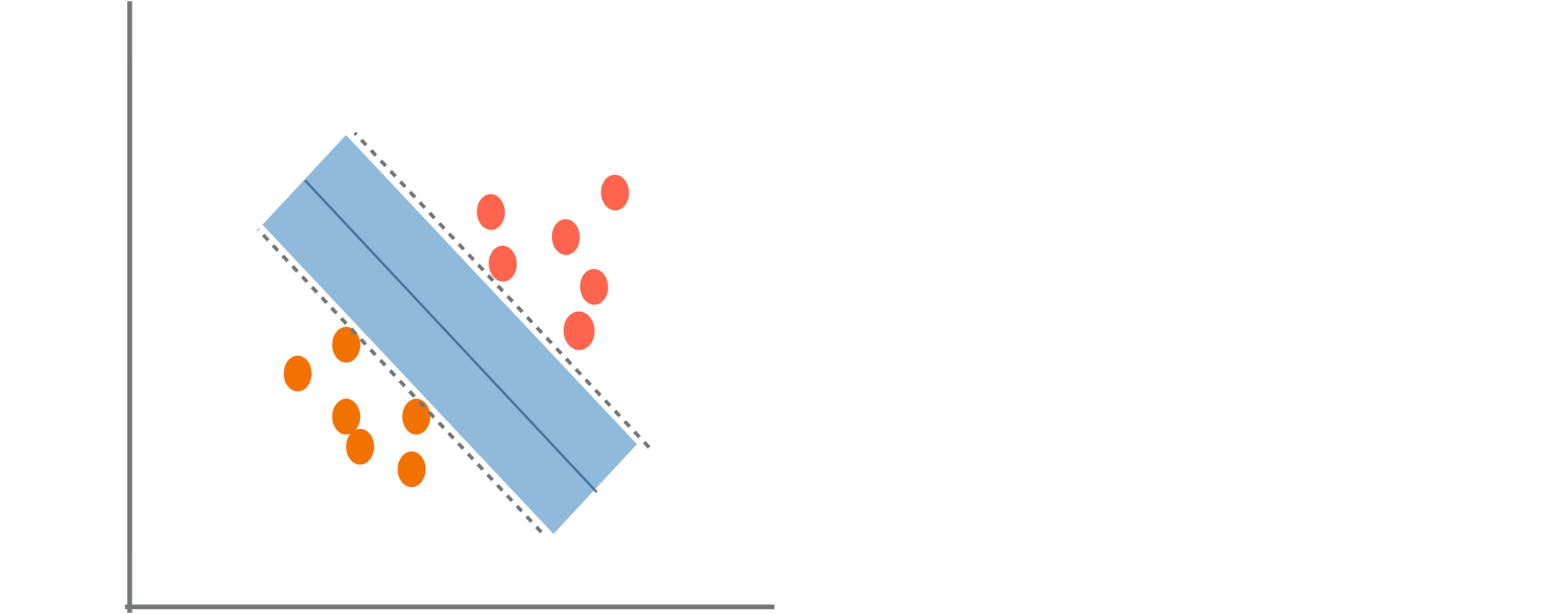
🟢 ข้อดี
- ใช้ได้ดีกับ High Dimensional Dataset
- ทำงานกับ Dataset ขนาดเล็กได้
- สามารถแก้ปัญหา Non-Linear ได้
🔴 ข้อเสีย
- ไม่มีประสิทธิภาพ สำหรับ Dataset ขนาดใหญ่
- ต้องเลือก Kernel ได้อย่างถูกต้อง
Decision Tree
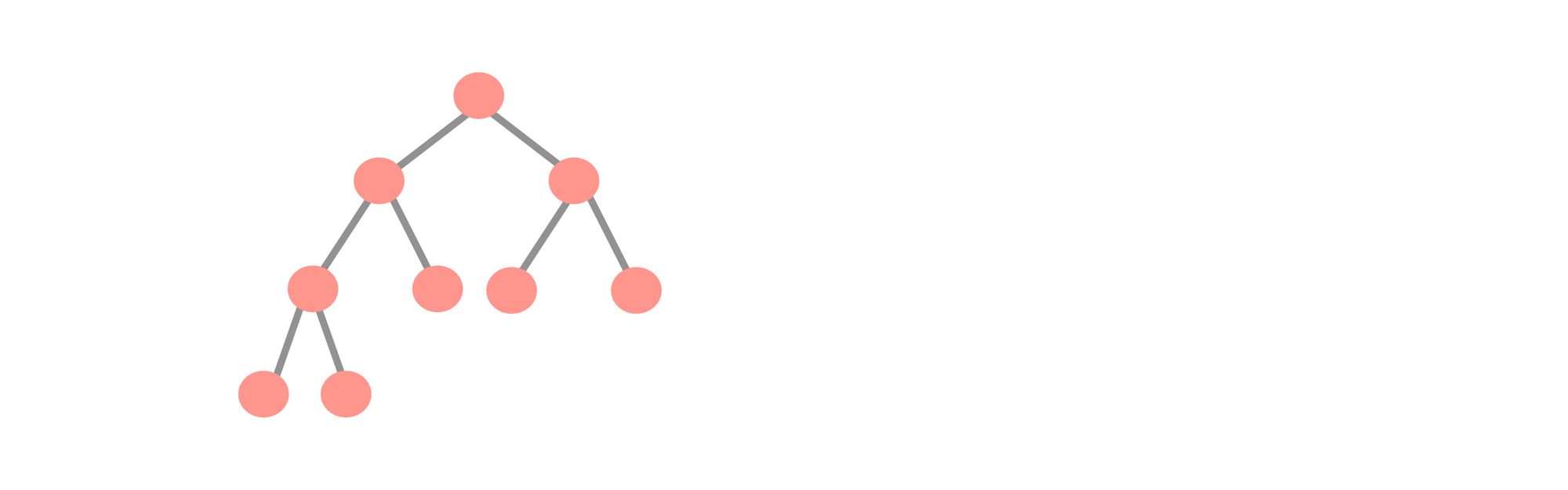
🟢 ข้อดี
- สามารถแก้ปัญหา Non-Linear ได้
- ทำงานกับ High Dimensional Dataset ได้ และให้ผลลัพธ์ที่ดี
- ง่ายในการอธิบาย และ Visualization
🔴 ข้อเสีย
- เกิด Overfitting ได้ อาจต้องแก้ไขโดยใช้ Random Forest
- การเปลี่ยนแปลงของข้อมูลเล็กน้อย ทำให้เปลี่ยนโครงสร้างของ Tree
- การคำนวณอาจซับซ้อนมาก
K Nearest Neighbor
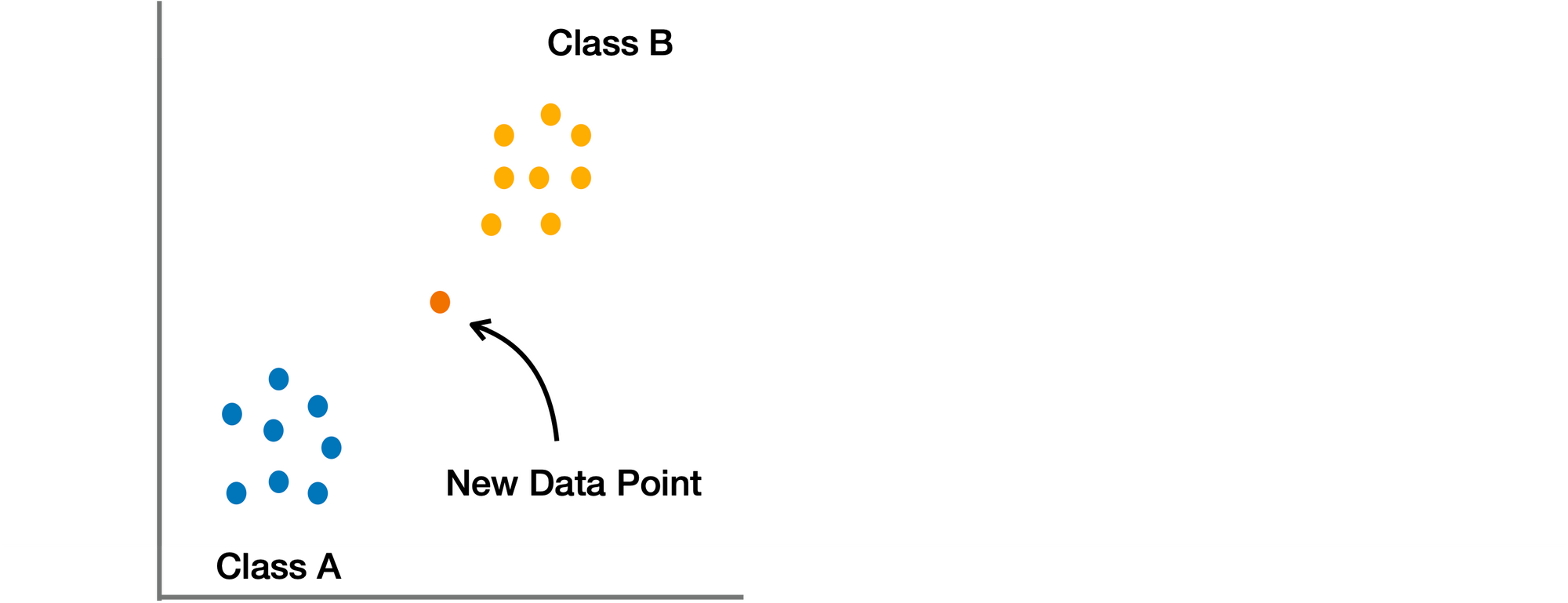
🟢 ข้อดี
- สามารถทำนายได้ โดยปราศจากการ Train
- ความซับซ้อนในการคำนวณ คือ O(n)
- สามารถใช้ได้ทั้ง Classification และ Regression
🔴 ข้อเสีย
- ทำงานได้ไม่ดี กับ Dataset ขนาดใหญ่
- ไวต่อ Noise, Missing Values และ Outliers
- ต้องทำ Feature Scaling
- ต้องเลือกค่า K ที่เหมาะสม
K Means
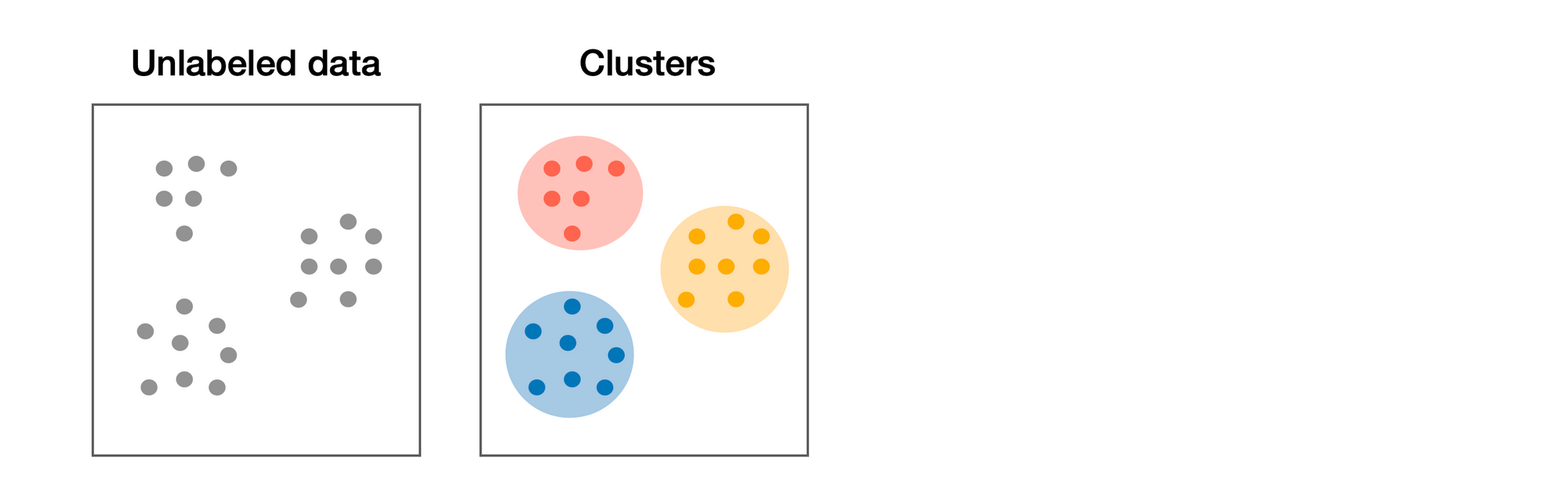
🟢 ข้อดี
- นิยม และ ง่ายในการ Implement
- Scale ไปยัง Dataset ขนาดใหญ่ได้ เวลาในการประมวลผลเร็ว
- มี Libraries จำนวนมากรองรับ
🔴 ข้อเสีย
- ต้องเลือกค่า K ที่เหมาะสม
- ไวต่อ Outliers และ Scales
- ค่าเริ่มต้น (Initial Random) ต้องเหมาะสม
- เหมาะกับรูปร่างทรงกลม
Principal Component Analysis (PCA)
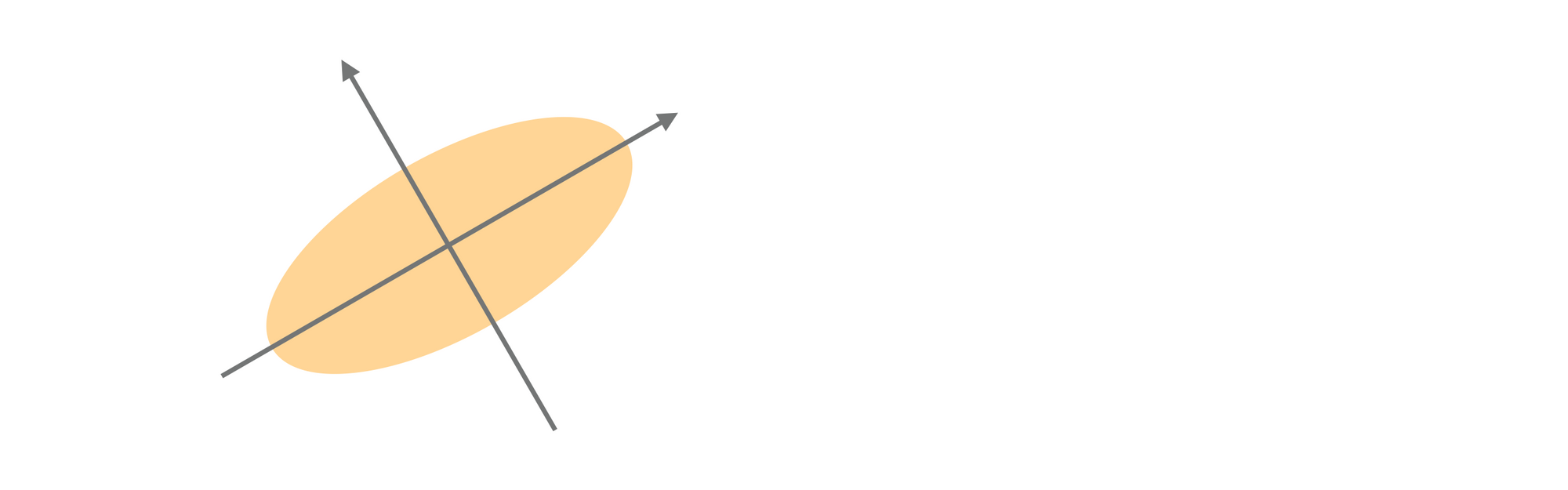
🟢 ข้อดี
- ลด Correlated Features
- ช่วยเพิ่มประสิทธิภาพ Model
- ลด Overfitting
🔴 ข้อเสีย
- Principal Component สามารถอธิบายได้ยาก
- สูญเสีย Information
- ต้องทำการ Standardization Data ก่อนทำ PCA
Naïve Bayes
🟢 ข้อดี
- ช่วงเวลาในการ Train น้อย
- ใช้ได้กับ Input ที่เป็น Category
- ง่ายในการ Implement
🔴 ข้อเสีย
- สมมติฐาน คือ ทุก Features เป็นอิสระจากกัน ซึ่งพบในยาก Dataset จริง
- Zero Frequency
- การประมาณ (Estimation) อาจผิดในบางกรณี
Artificial Neural Network (ANN)
🟢 ข้อดี
- สามารถเรียนรู้ ความสัมพันธ์ที่เป็น Non-Linear หรือ Complex
- มี Fault Tolerence
- สามารถ Generalize กับ Unseen Data ได้
🔴 ข้อเสีย
- ใช้เวลาในการ Train นาน
- ไม่ได้ Guarantee ว่าจะ Convergence
- เป็น Black Box อธิบายได้ยาก
- ต้องใช้ Hardware ประสิทธิภาพสูง