Intro to Machine Learning (Ep.1/2)

เนื้อหา
- ทำไมถึงต้องมี Machine Learning (ML)
- Part 1 : Classical Machine Learning (Traditional ML)
- 1.1) Supervised I) Classification II) Regression
- 1.2) Unsupervised I) Clustering II) Dimensionality Reduction III) Association Rule
- Part 2 : Reinforcement Learning (RL)
- Part 3 : Ensemble Methods
- I) Stacking II) Bagging III) Boosting
- Part 4 : Neural Network (NN) & Deep Learning (DL)
ทำไมถึงต้องมี Machine Learning (ML)
- หากเราต้องการซื้อรถ และ คำนวณว่า ต้องเก็บเงินเท่าไร ต่อ เดือน ราคารถใหม่ คือ 1,000,000 แต่ราคารถมือสอง 1 ปี คือ 800,000 ใช้แล้ว 2 ปี 750,000
- ทำให้เห็นรูปแบบว่า ราคารถขึ้นอยู่กับอายุของมัน และ ลดลง 50,000 ทุกปี แต่จะไม่ต่ำกว่า 300,000 บาท
- ใน ML จะเรียกว่า "การถดถอย (Regression)" เราทำนายค่า (ราคา) จากข้อมูลที่เรารู้ในอดีต เช่น เมื่อต้องการประเมินราคาที่เหมาะสมของ iPhone มือสอง หรือ จะซื้อเบียร์กี่ขวด สำหรับงานปาร์ตี้?
- เป็นเรื่องที่ดี หากมีสูตรง่าย ๆ สำหรับทุก ๆ ปัญหาบนโลก แต่ความจริงไม่ใช่อย่างนั้น
- กรณีของรถยนต์ ปัญหานี้มีหลายปัจจัยที่เกี่ยวข้อง เช่น วันผลิต Options ที่แตกต่างกัน เงื่อนไขทางเทคนิค ความต้องการ (อุปสงค์) ของตลาด และ ปัจจัยอื่น ๆ ที่ซ่อนไว้อีกมากมาย
- เราไม่สามารถเก็บข้อมูลทั้งหมดไว้ในหัว และคำนวณ "ราคารถ"
- คนมีข้อจำกัด เราต้องการให้หุ่นยนต์ทำงานเรื่องคณิตศาสตร์แทนเรา หากให้ข้อมูลกับ Machine และ ขอให้ค้นหา Patterns (รูปแบบ) ที่ซ่อนอยู่ทั้งหมดที่เกี่ยวข้องกับ "ราคารถ"
- Machine สามารถทำงานแบบนี้ได้ และยิ่งไปกว่านั้น คือ มันทำได้ดีกว่าคน เป็น "จุดกำเนิด ของ ML"
3 องค์ประกอบของ ML
- เป้าหมายเดียวของ ML คือ การทำนายผลลัพธ์ ตามข้อมูล Input (งาน ML ทั้งหมด สามารถแสดงได้ด้วยวิธีนี้)
- ความหลากหลายในข้อมูลตัวอย่างที่มี ทำให้เราสามารถหา Patterns ที่เกี่ยวข้อง และทำนายผลลัพธ์
- มี 3 องค์ประกอบของ ML
1) Data
- หากต้องการตรวจจับ Spam email >> ต้องมีข้อมูลตัวอย่าง Spam
- หากต้องการทำนายราคาหุ้น >> ต้องมีข้อมูลราคาในอดีต
- หากต้องการตั้งค่าผู้ใช้ตามความชอบ >> อาจวิเคราะห์ข้อมูลจากกิจกรรมบน Facebook
ยิ่งข้อมูลมีความหลากหลายมากขึ้นเท่าไร ผลลัพธ์จะดีขึ้นเท่านั้น (ใน ML ที่มีข้อมูลน้อย ก็ควรจะมีเป็นหลักหมื่น)
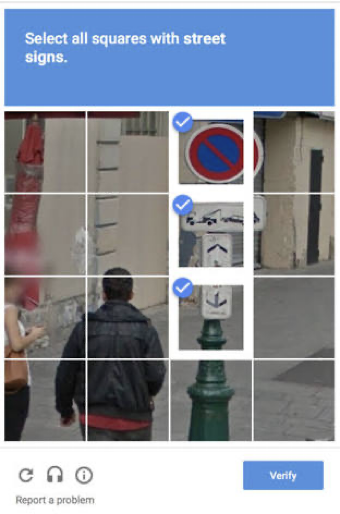
2 วิธี ในการได้มาซึ่งข้อมูล (Manual, Auto)
- Manual : ความผิดพลาดน้อย แต่ต้องใช้เวลา และ มีต้นทุนสูง
- Auto : ต้นทุนต่ำกว่า เช่น Google ให้ลูกค้า ช่วย label ผ่าน ReCaptcha
2) Features : รู้จักกันในชื่อว่า (Parameters) พารามิเตอร์ หรือ (Variables) ตัวแปร สิ่งเหล่านี้อาจเป็น ไมล์รถยนต์ เพศของผู้ใช้งาน ราคาหุ้น จำนวนคำในข้อความ อีกนัยหนึ่ง คือ เป็นตัวแปร เพื่อให้ Machine ใช้ในการพิจารณา
- เป็นเรื่องง่าย ที่พิจารณา ข้อมูลที่ถูกเก็บไว้ในตาราง เพราะ Features คือ ชื่อคอลัมน์
- แต่หากเรามีรูปแมวขนาด 100 GB ? เราไม่สามารถพิจารณาแต่ละพิกเซลเป็น Features เป็นเหตุผลว่า การเลือก Features ที่เหมาะสม ใช้เวลานานกว่าขั้นตอนอื่น ๆ และอาจเกิดข้อผิดพลาดได้ ควรหลีกเลี่ยงการเลือกด้วยสัญชาตญาณมนุษย์ เพราะอาจจะเลือกเฉพาะ Features ที่เราสนใจ (มี Bias)
3) Algorithms : ในแต่ละปัญหา สามารถแก้ไขด้วยวิธีต่างกัน วิธีที่เลือกใช้ ต้องมีความเที่ยงตรง (Precision) มีประสิทธิภาพ และ มีขนาดของ Model ที่จะใช้งาน เหมาะสม สิ่งสำคัญอันหนึ่ง คือ หากข้อมูล Input ไม่ดี แม้แต่ Algorithm ที่ดีที่สุดก็ช่วยอะไรไม่ได้ "garbage in - garbage-out" ดังนั้น ไม่ควรให้ความสำคัญกับ ค่าความแม่นยำ (Accuracy) มากเกินไป ควรหาข้อมูล Input มาใส่เพิ่มเติม
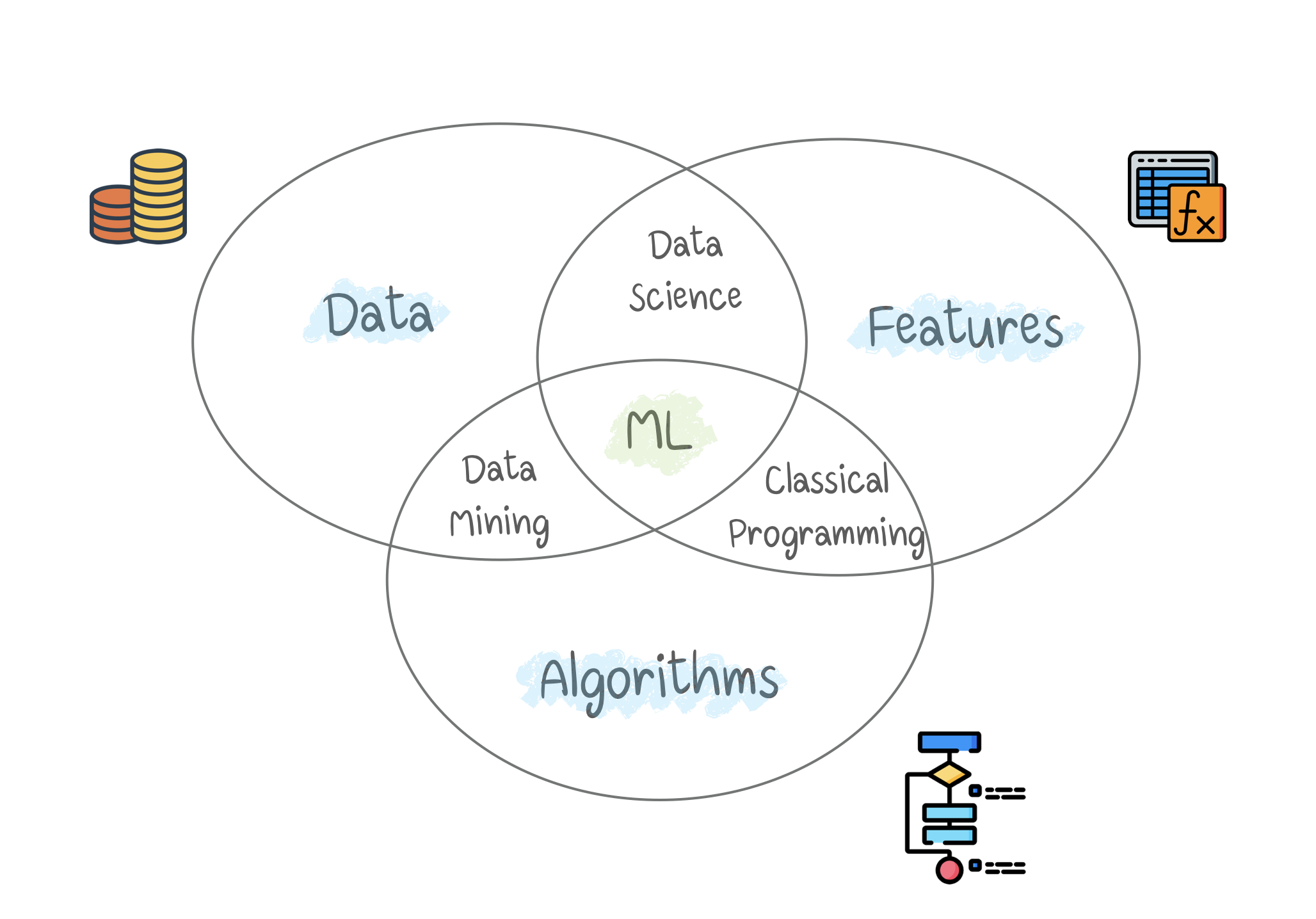
“การเรียนรู้” กับ “สติปัญญา”
- Artificial Intelligence (AI) : เป็นชื่อขอบเขตความรู้ทั้งหมด
- Machine Learning (ML) : เป็นส่วนหนึ่งของ AI
- Neural Network (NN) : หนึ่งในประเภทของ ML ที่นิยม แต่ยังมีวิธีที่ดีกว่า คือ DL
- Deep Learning (DL) : วิธีการใหม่ โดย Train NN ด้วยสถาปัตยกรรมใหม่
Note : กฎ คือ การเปรียบเทียบ ควรจะต้องเป็นสิ่งที่อยู่ระดับเดียวกัน การเปรียบเทียบว่า นำเอา NN มาแทน ML ก็เหมือนเอา "ล้อรถ" มาแทน "รถยนต์" (เปรียบเทียบกันไม่ได้)
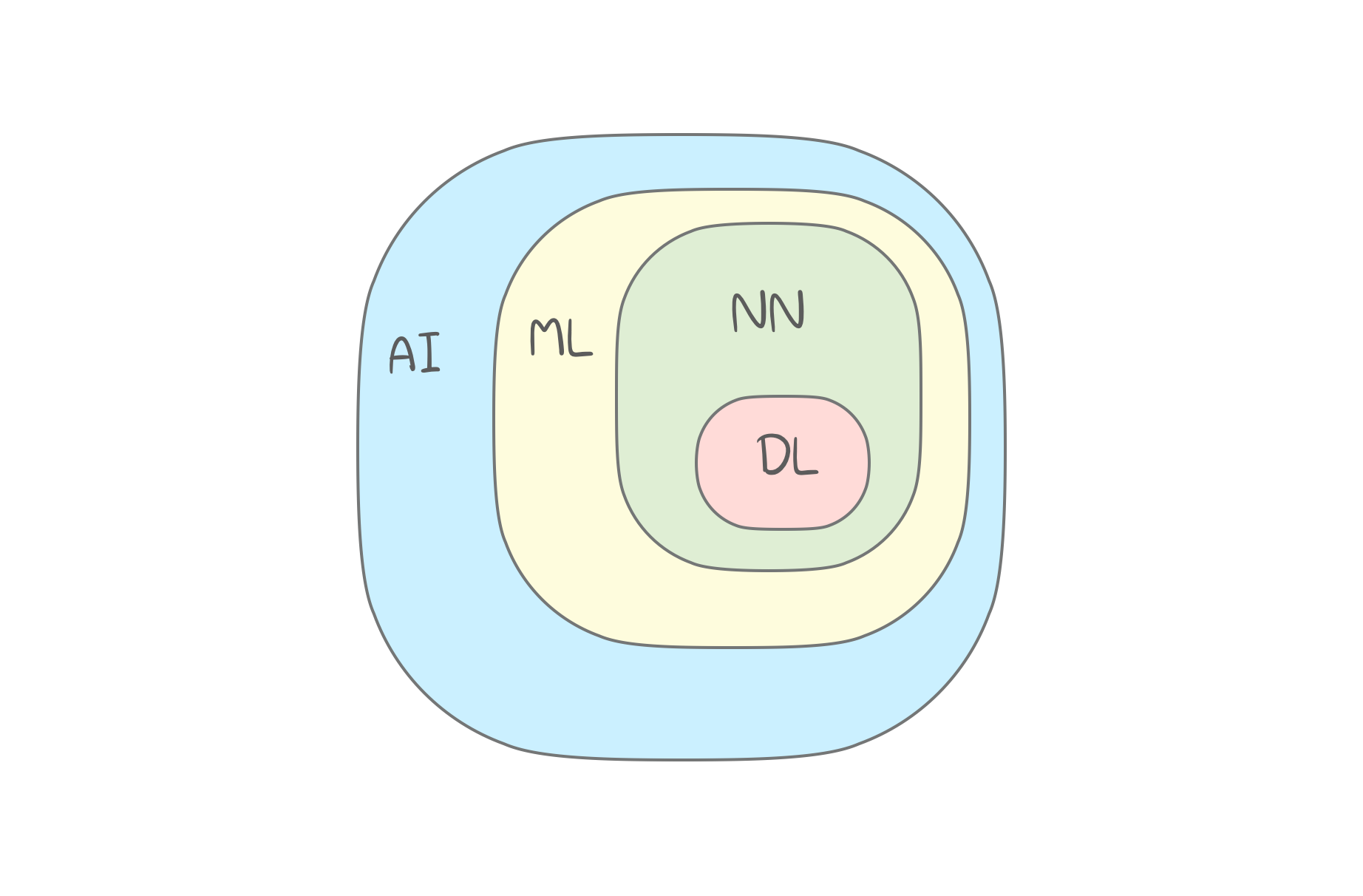
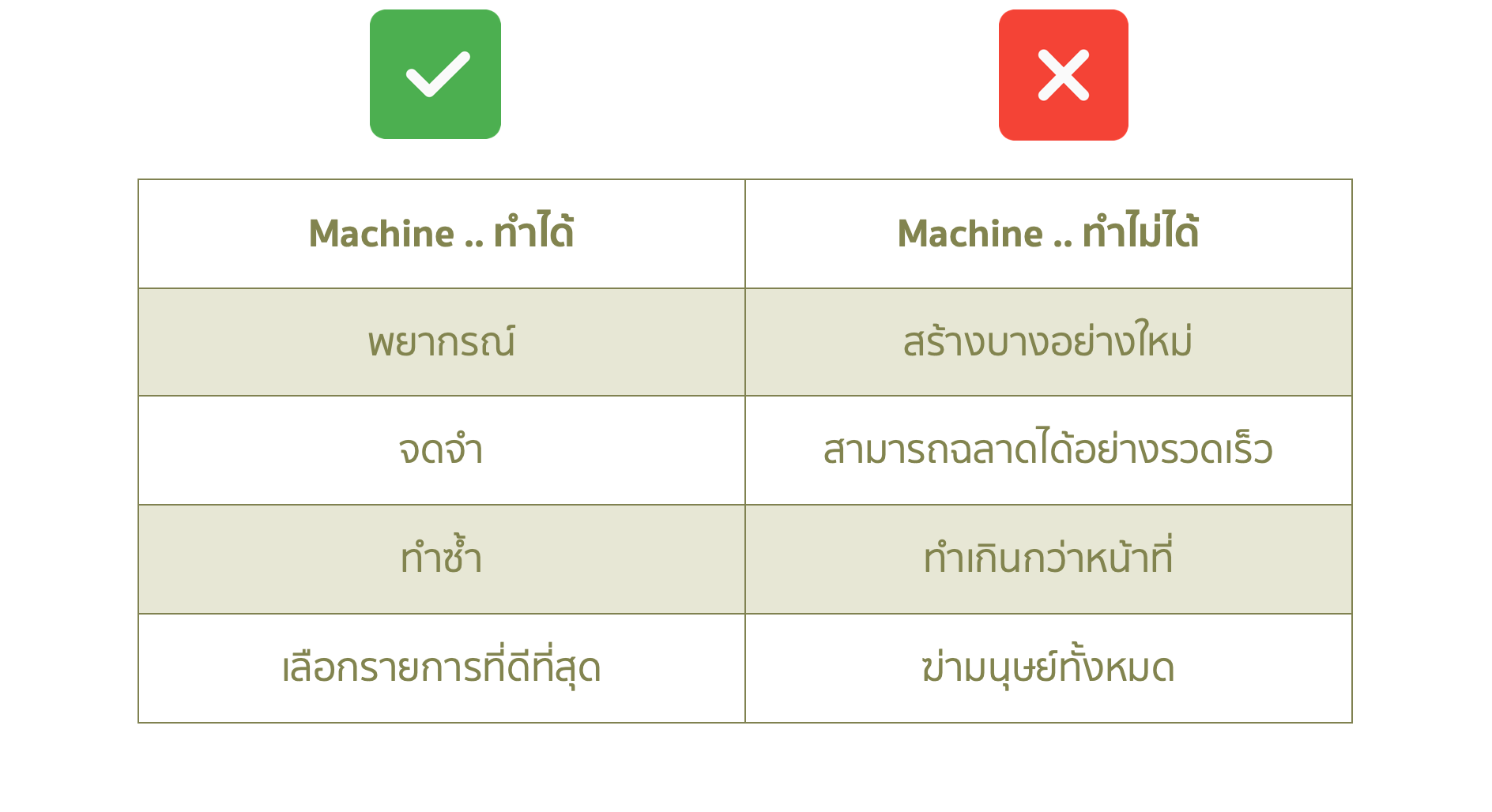
Diagram ของ ML
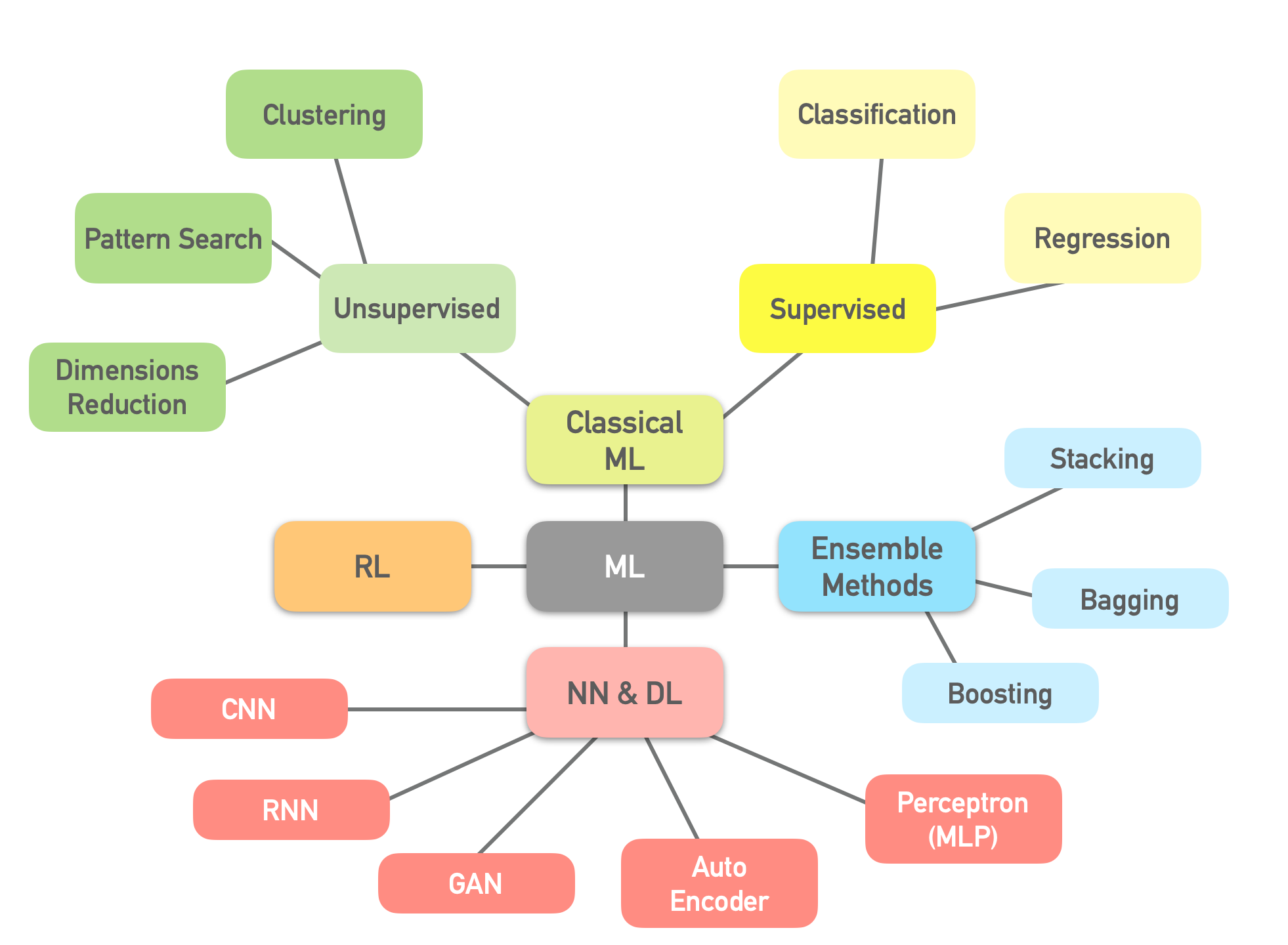
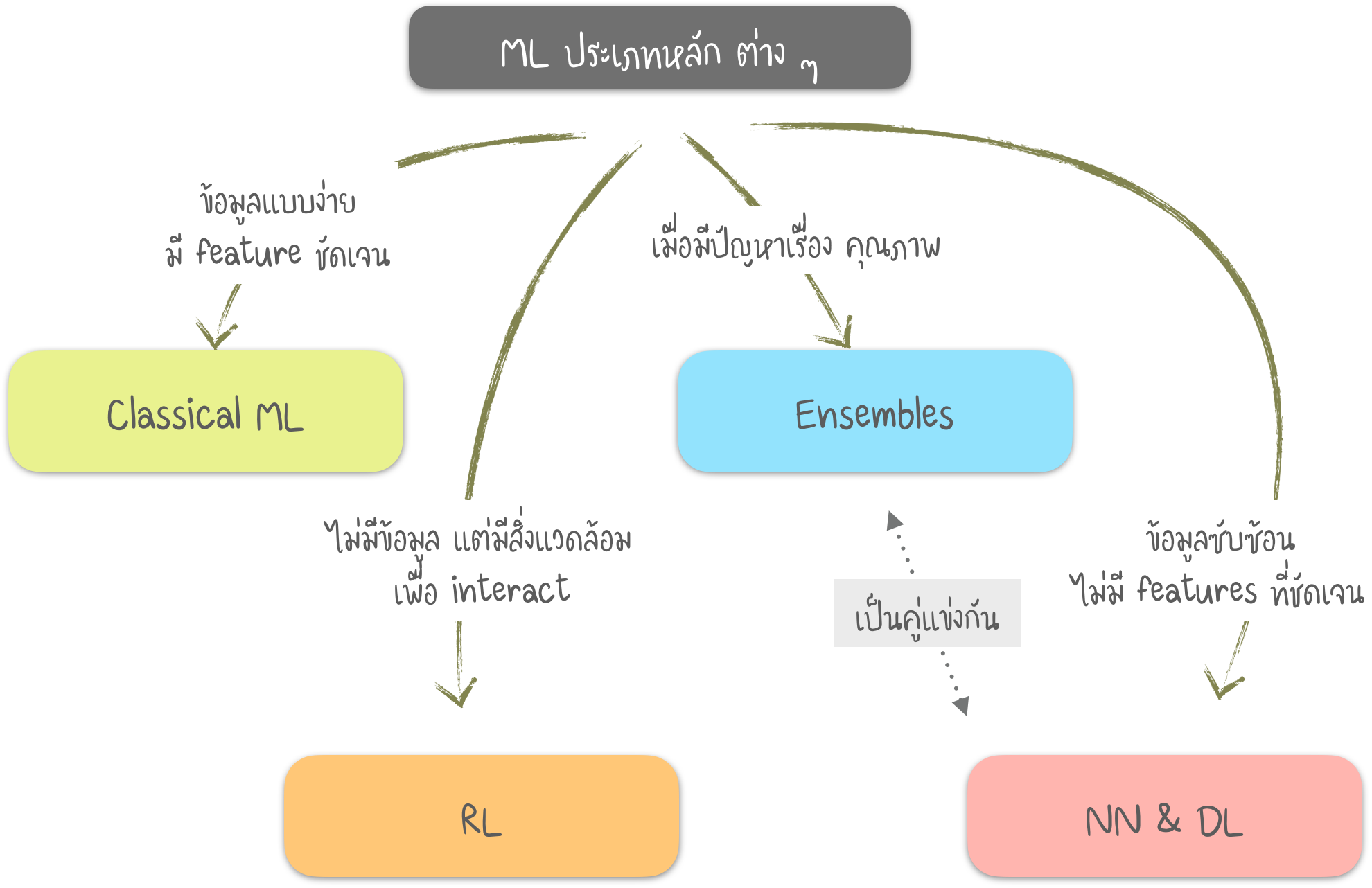
Part 1 : Classical ML
- วิธีการแรกมาจากสถิติ ในยุค 1950 อยู่ในหลักของคณิตศาสตร์ เช่น ค้นหารูปแบบ (Pattern) จากตัวเลข ประเมินความใกล้ของจุดข้อมูล คำนวณทิศทางเวคเตอร์
- เช่น เมื่อเราเห็นรายการของบทความเพื่อ "อ่านต่อ" ธนาคารบล็อคบัตรของเรา ขณะที่เติมน้ำมันในปั้ม ซึ่งไกลมากแห่งหนึ่ง
- บริษัท Tech ขนาดใหญ่ ชอบที่จะใช้ NN เพราะว่า การเพิ่ม 2% ของ ความแม่นยำ หมายถึง รายได้ที่เพิ่มขึ้น 2,000 ล้าน แต่จะไม่สมเหตุสมผล หากเราอยู่ใน บริษัท (หรือ ข้อมูล) ขนาดเล็กกว่า มีเรื่อง เกี่ยวกับทีมที่ใช้เวลา 1 ปี พัฒนา Recommendation Algorithm ใหม่ สำหรับเว็บไซต์อีคอมเมิร์ซ ก่อนที่จะพบว่า 99% ของการเข้าชมมาจาก Search Engine ดังนั้น Algorithm ที่ทำขึ้น ไม่มีประโยชน์ เพราะผู้ใช้ส่วนใหญ่ไม่ได้เปิดหน้าเว็ปไซต์หลัก
- ข้อดีอีกอย่าง ของ "ML ดั้งเดิม" คือ เราอธิบายได้ง่าย เพราะมันเป็นวิธีพื้นฐานที่ใคร ๆ ก็เข้าใจได้
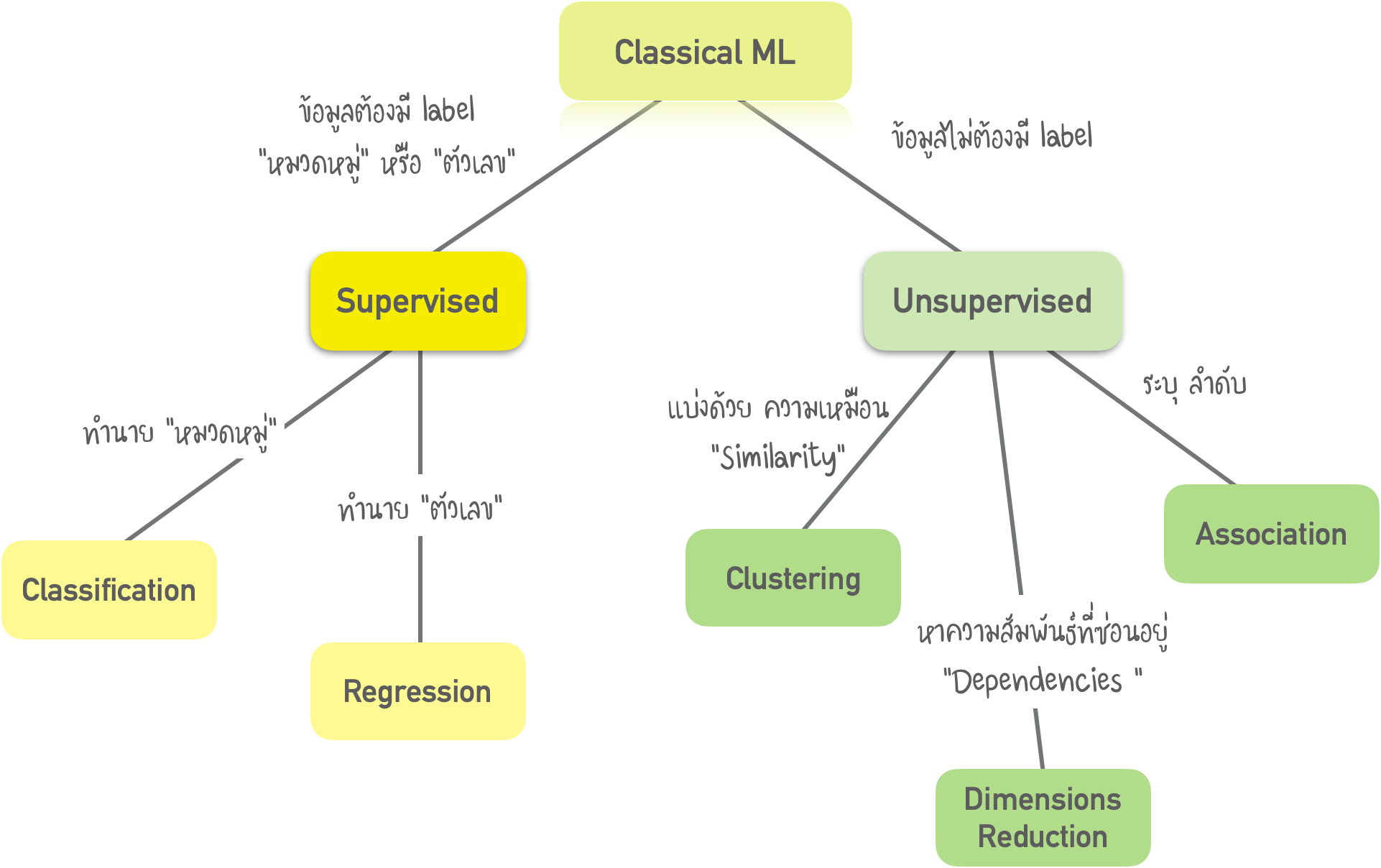
ML แบบดั้งเดิม แบ่งได้เป็น 2 ประเภท คือ 1.1) Supervised 1.2) Unsupervised
1.1) Supervised กรณีแรก Machine มี "Supervisor" หรือ "ครู" ที่ให้คำตอบทั้งหมด เช่น แมวหรือสุนัขในภาพ ครูได้แบ่ง / ติดป้าย - "Label" ข้อมูลออกเป็นแมวและสุนัข และ Machine ใช้ตัวอย่างเหล่านี้เพื่อเรียนรู้
1.2) Unsupervised คือ Machine ถูกทิ้งให้อยู่กับตัวเอง พร้อมรูปภาพสัตว์ โดยข้อมูลไม่ได้ระบุคำตอบ Machine พยายามหารูปแบบ (Patterns) ต่าง ๆ ด้วยตนเอง ซึ่งจะพูดถึงวิธีการนี้ในส่วนถัด ๆ ไป
1.1) Supervised Learning
- แน่นอนว่า Machine จะเรียนรู้ได้เร็วขึ้นด้วย Supervisor ดังนั้น มันจึงถูกนำไปใช้ในงานจำนวนมาก แบ่งงานได้ 2 ประเภท
I) Classification - ทำนายหมวดหมู่ของวัตถุ
II) Regression - ทำนายค่าตัวเลข
I) Classification
- แยกวัตถุตามคุณลักษณะอย่างใดอย่างหนึ่ง ที่รู้ก่อนล่วงหน้า เช่น แยกถุงเท้าด้วยสี แยกเอกสารตามภาษา แยกเพลงตามประเภท
ตัวอย่างที่นำไปใช้
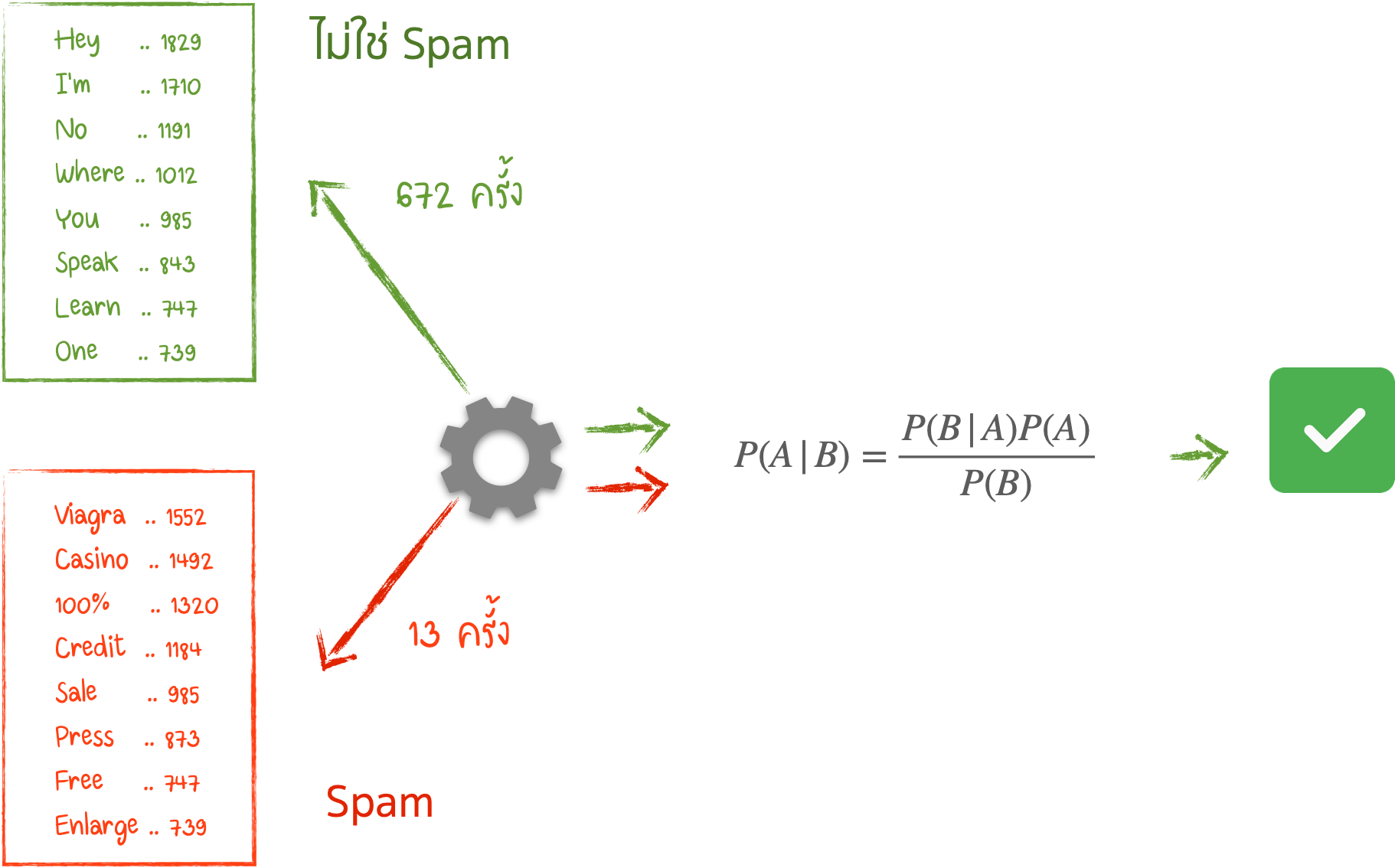
- การกรองสแปม (Spam Filtering)
- ตรวจจับภาษา (Language Detection)
- ค้นหาเอกสารที่คล้ายกัน (Search of Similar Documents)
- การวิเคราะห์ความรู้สึก (Sentiment Analysis)
- จำแนกตัวอักษรและตัวเลขที่เขียนด้วยลายมือ (Recognition of Handwritten Characters & Numbers)
- ตรวจจับการโกง (Fraud Detection)
- Algorithms ที่นิยม : Naive Bayes, Decision Tree, Logistic Regression, K-Nearest Neighbors, Support Vector Machine
การตรวจจับ Spam (Naive Bayes)
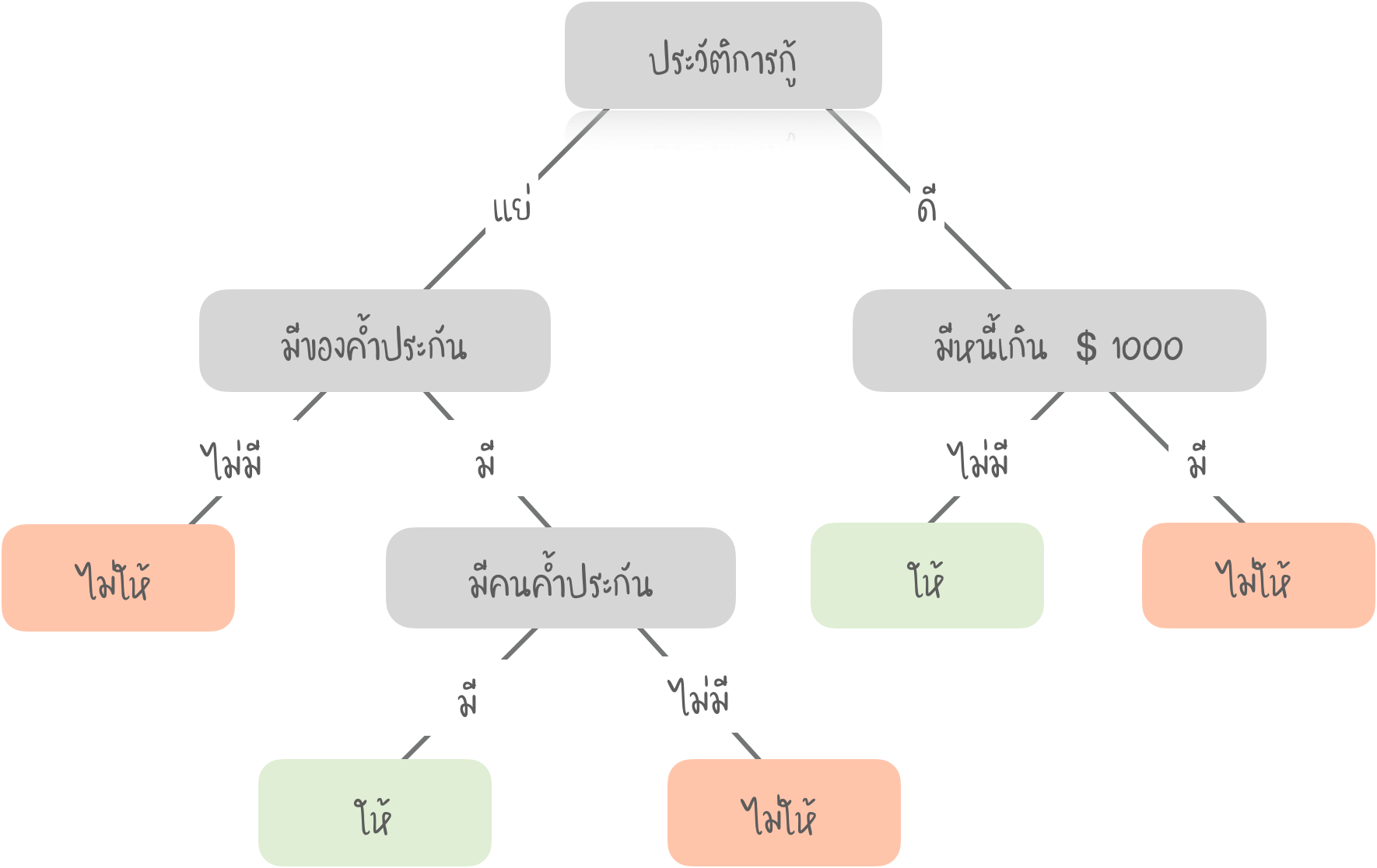
การให้เงินกู้ (Decision Tree)
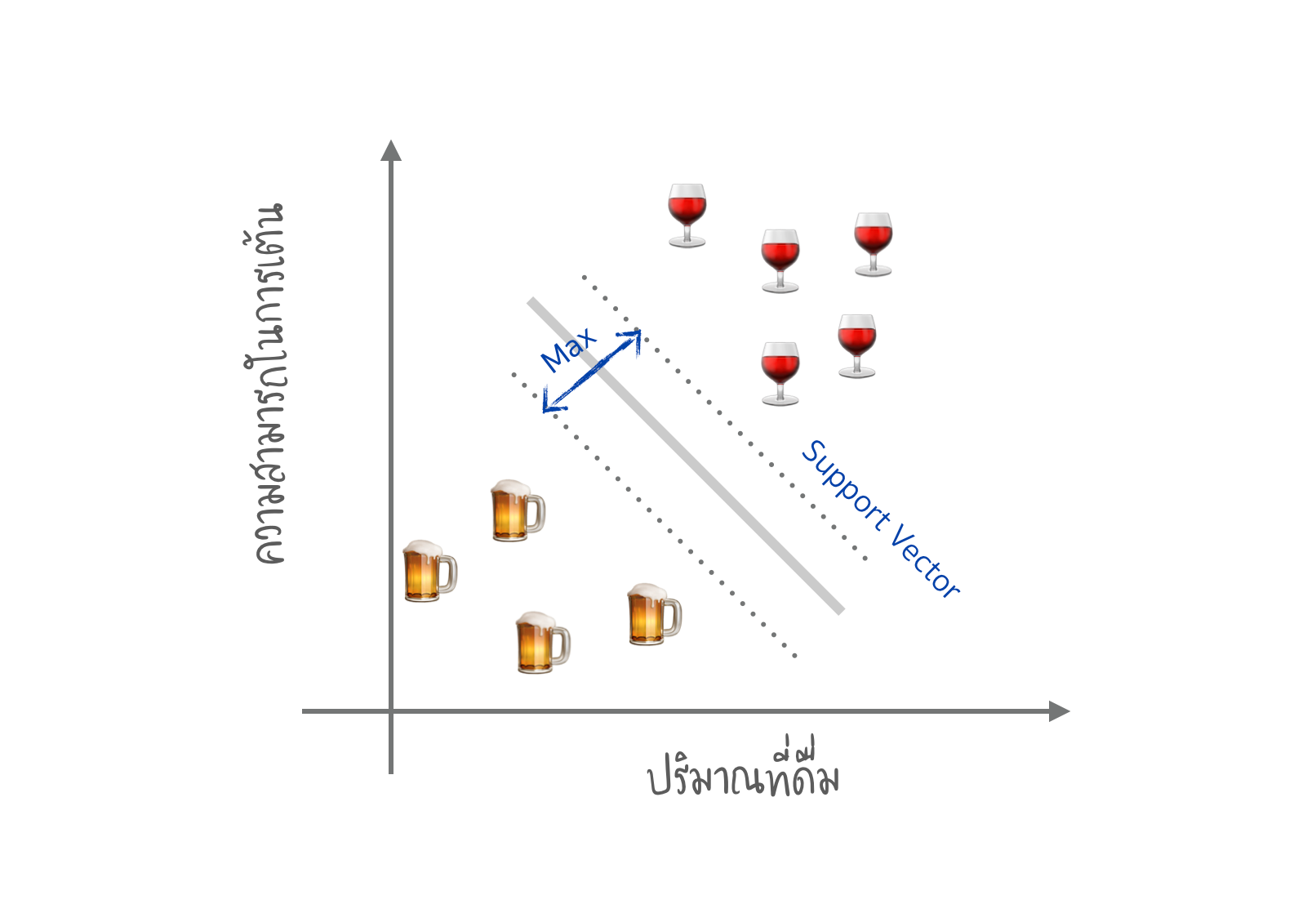
การแยกประเภทเครื่องดื่ม (Support Vector Machine)
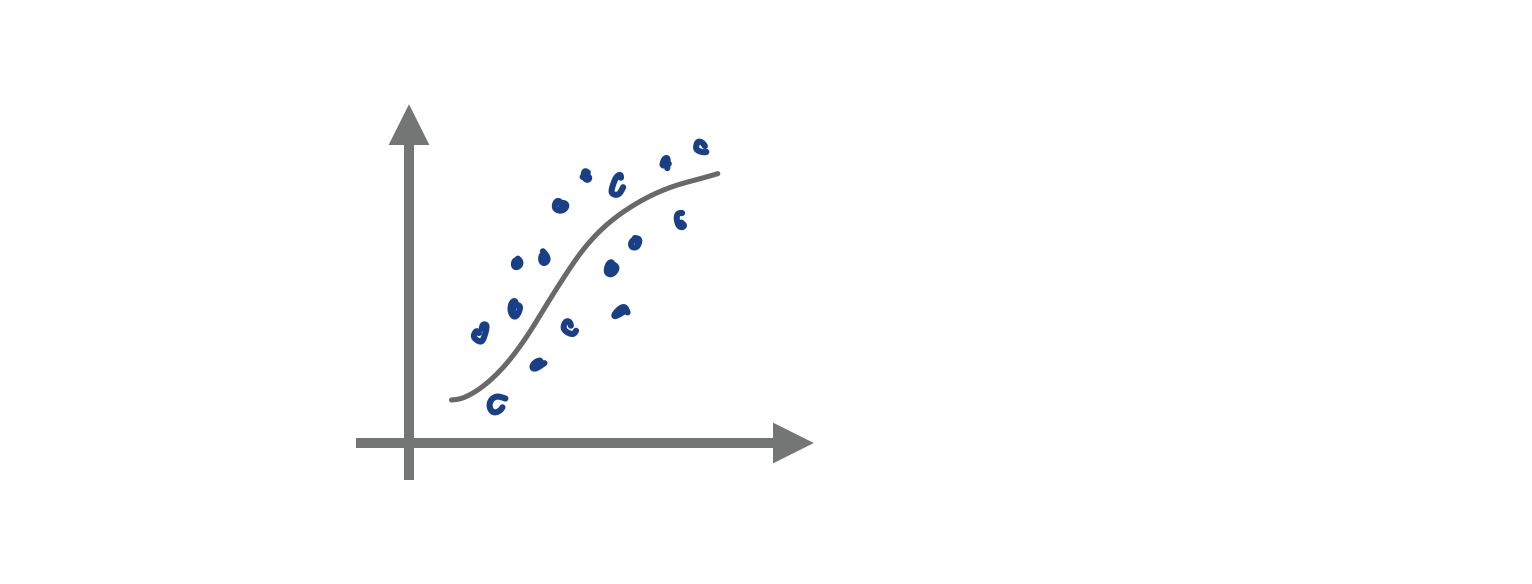
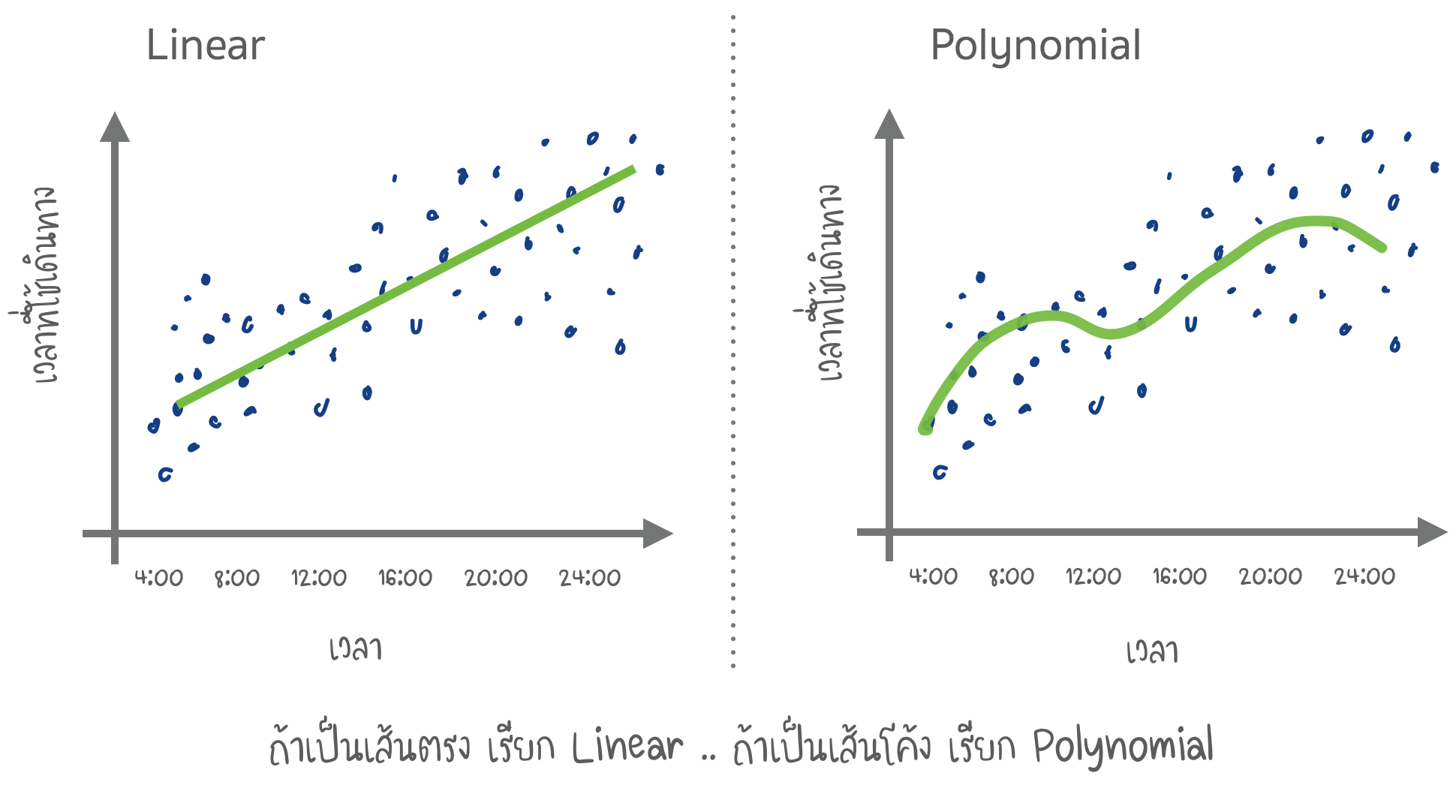
II) Regression
มันคือ การลากเส้นหนึ่งผ่านจุดทั้งหมดเหล่านี้
ตัวอย่างที่นำไปใช้
- ทำนายราคาหุ้น
- การวิเคราะห์ อุปสงค์ & ปริมาณการขาย
- การวินิจฉัยทางการแพทย์
- อะไรก็ตาม .. ที่เกี่ยวกับ ตัวเลข - เวลา
- Algorithms ที่นิยม : Linear & Polynomial Regression
ทำนายการจราจร (Linear and Polynomial Regression)
1.2) Unsupervised Learning
- Unsupervised ถูกคิดค้นขึ้นช่วง 1990 ถูกนำไปใช้น้อยกว่า เพราะบางครั้งเราไม่มีทางเลือก
- ข้อมูลที่มากับ Label เป็นเรื่องที่ดี หากเราต้องการจำแนกรถเมล์ การถ่ายรูปรถเมล์ ล้านรูป บนถนน แล้วบอกว่าเป็นรูปรถเมล์ อาจต้องใช้เวลาทั้งชีวิต
- ดังนั้น เราอาจจะให้คนช่วย Label ด้วยค่าแรงที่ถูก $0.05 หรือ ใช้วิธีการแบบ Crowdsourcing หรือ เราอาจใช้ Unsupervised แต่ไม่ค่อยเห็นใช้เป็น Algorithm หลัก ในทางปฏิบัติมากนัก ส่วนใหญ่จะใช้ในการทำ EDA (Exploratory Data Analysis)
I) Clustering
- Clustering คือ การจำแนกประเภทวัตถุ ที่ไม่มี Class กำหนดไว้ล่วงหน้า Algorithm ทำการ Cluster โดยพยายามค้นหาวัตถุที่คล้ายกัน (โดยคุณสมบัติบางอย่าง) และรวมไว้ใน Cluster โดยใช้ Algorithm บางอย่าง เราสามารถระบุจำนวนกลุ่มที่ต้องการได้
- ตัวอย่างของ Clustering เช่น การแสดงจุด (Markers) บนเว็ปแผนที่ เมื่อเรากำลังหาร้านอาหารมังสวิรัติ Clustering จะพยายามจัดกลุ่มเพื่อแสดงร้านที่เราน่าจะสนใจออกมา แทนที่จะแสดงร้านทั้งหมด 3 ล้านแห่ง ซึ่งอาจทำให้ Browser ค้างได้
- Apple Photos และ Google Photos ใช้การ Cluster ที่ซับซ้อน เพื่อมองหาใบหน้าในภาพถ่าย และสร้างอัลบั้มรูปเพื่อนให้เรา
- อีกตัวอย่างที่นิยมใช้ คือ การบีบอัดภาพ เมื่อบันทึกภาพไฟล์ PNG หากเราตั้งค่า Palette เป็น 32 สี Clustering จะคำนวณ "ค่าเฉลี่ยสีแดง" และตั้งค่าสำหรับ Pixel สีแดงทั้งหมด หากใช้ สีน้อยลง จะทำให้ ขนาดไฟล์เล็กลง
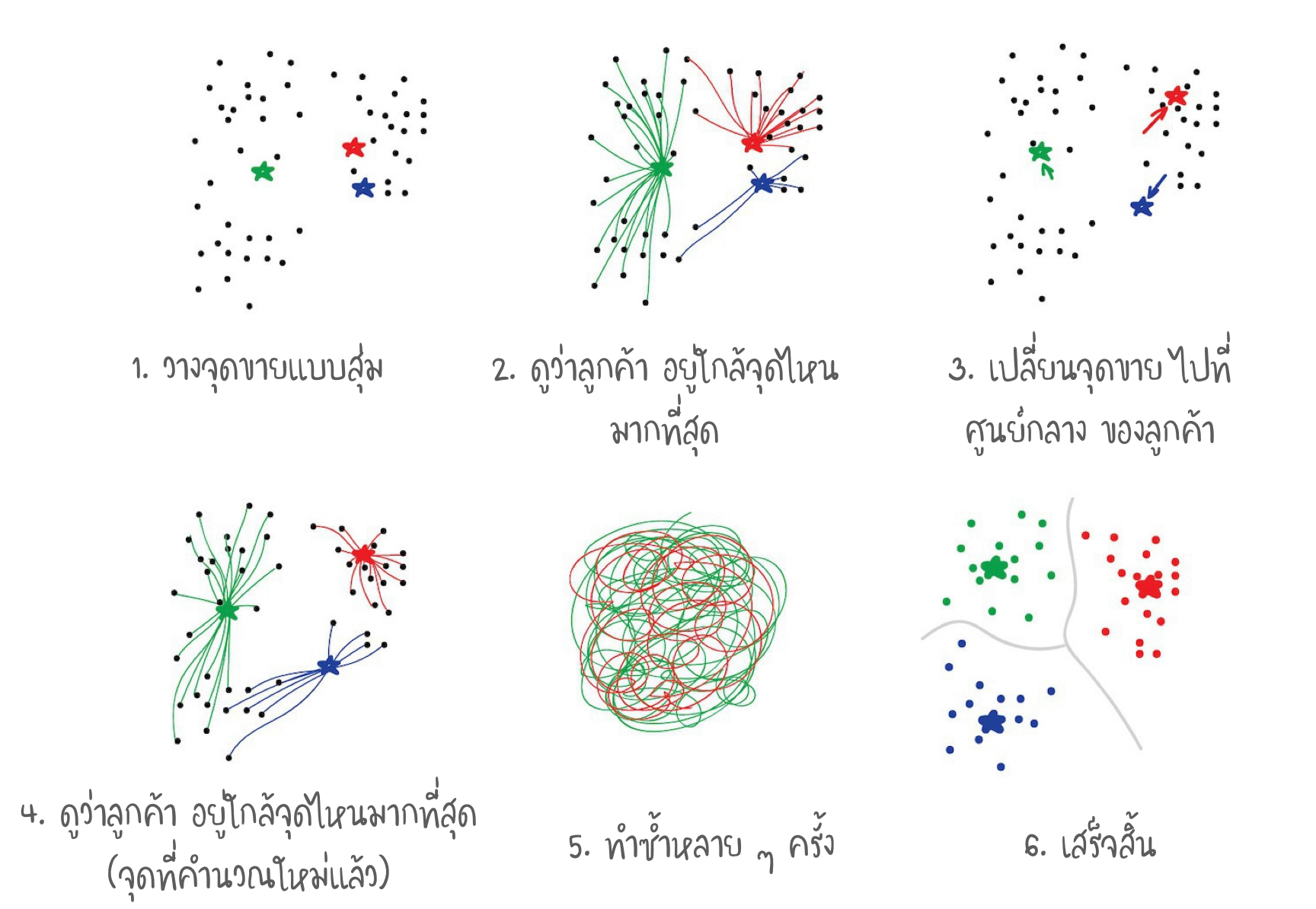
วิธีการของ Algorithm แบบ K-Means
- สุ่มตั้งค่า 32 จุดสีในจานสี ในทีนี้ คือ ศูนย์กลาง (Centroid) จุดทั้งหมด จะถูกกำหนดให้อยู่กับ Centroid ที่ใกล้ที่สุด ดังนั้น เราจึงได้ทั้งหมด 32 กลุ่ม จากนั้นเราจะย้าย Centroid ไปยังใจกลางของกลุ่ม (คำนวณ Mean ใหม่) และทำซ้ำ จนกระทั่ง Centroid หยุดเคลื่อนไหว
- หรือ เราอาจมีปัญหากับสี เช่น สีที่เหมือนสีฟ้า มันเป็นสีเขียวหรือสีน้ำเงิน ?
ใช้ K-Means หาจุดขายกาแฟ ที่เหมาะสม
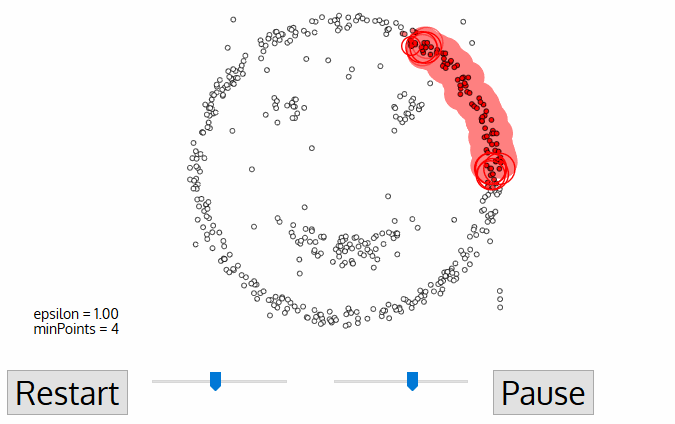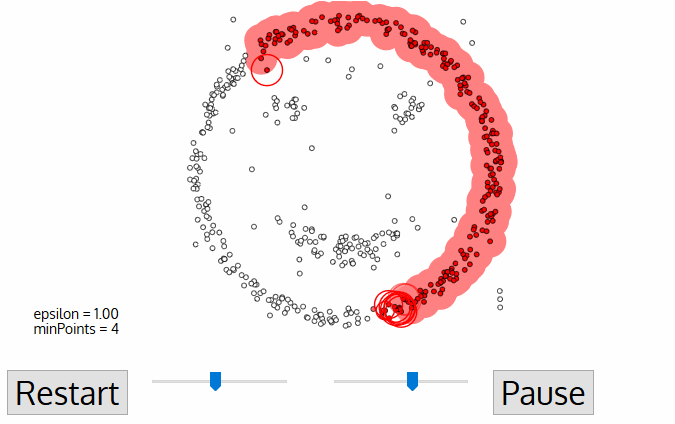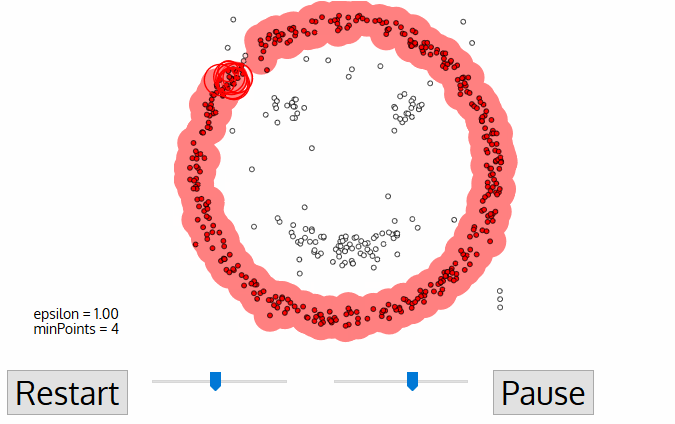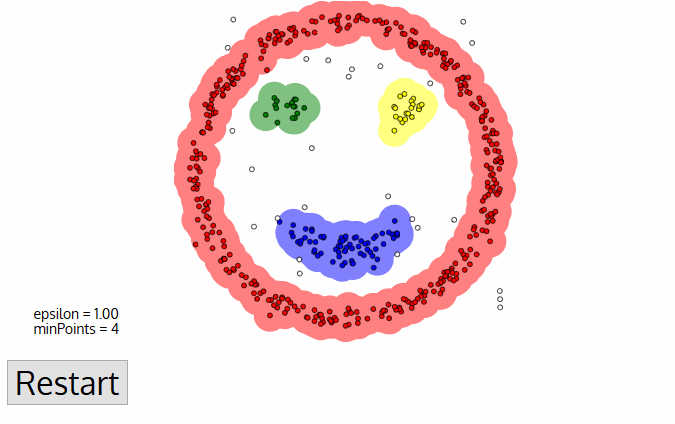
- การหา Centroid นั้น เป็นเรื่องง่าย แต่ในชีวิตจริง ทุก ๆ เรื่อง Cluster ไม่ใช่ รูปวงกลม เช่น นักธรณีวิทยา ต้องการหาแร่บนแผนที่ มันอาจเป็นรูปใด ๆ ก็ได้ และ เราไม่รู้จำนวนของมันว่ามีเท่าไร
- Algorithm อันหนึ่ง คือ DBSCAN อาจนำมาใช้ได้ การทำงานของมัน เปรียบเทียบได้กับ ให้ 3 คนที่ยืนใกล้กันจับมือกันไว้ เป็นกลุ่ม จากนั้นหากลุ่มข้างเคียง ที่เอื้อมถึง เพื่อจับมือกันอีก จนกระทั่งไม่สามารถจับมือใครได้ ถือเป็น Cluster ที่ 1 และทำแบบนี้ไปเรื่อย ๆ .. จนกระทั่งทุกคนมี Cluster อยู่

II) Dimensionality Reduction
การรวบรวม Features ที่กำหนด ให้มีระดับสูงขึ้น (High-Level)

ตัวอย่างที่นำไปใช้
- Recommender systems
- การแสดงผลที่มีประสิทธิภาพ
- หาเอกสารที่ใกล้เคียงกัน
- วิเคราะห์ภาพปลอม
- บริหารความเสี่ยง
- Algorithms ที่นิยม : Principle Component Analysis (PCA), Singular Value Decomposition (SVD), Latent Dirichlet allocation (LDA), Latent Semantic Analysis (LSA, pLSA, GLSA), t-SNE (สำหรับการแสดงผล)
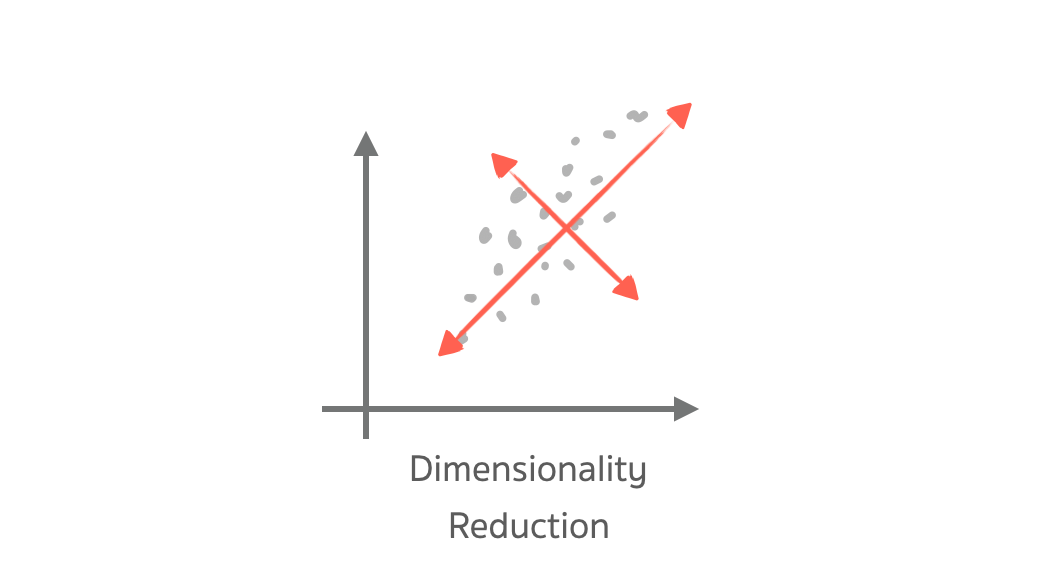
- การ Project ข้อมูล ไปยังเส้น PCA เพื่อลดรูป Features ของข้อมูล อาจทำให้สูญเสียบางอย่างไป แต่สิ่งเกิดขึ้นใหม่ อาจนำไปใช้ประโยชน์ได้มากกว่า คือ ทำให้ Train model ได้เร็วกว่า โอกาสเกิด overfit น้อยกว่า ใช้จำนวน features น้อยกว่า
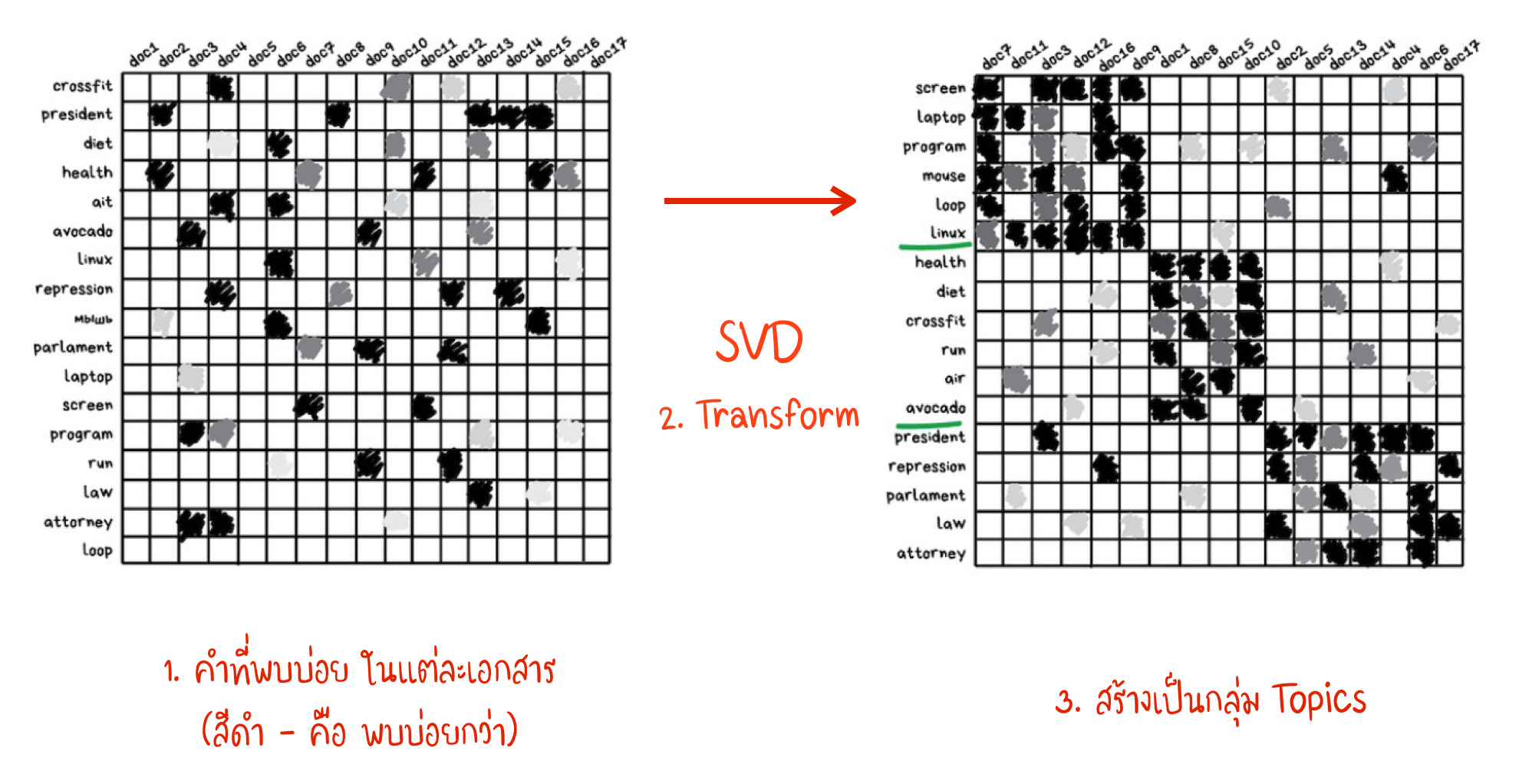
- Algorithms เหล่านี้ เป็นเครื่องมือที่สามารถสร้าง Topic modeling เราสามารถสรุป ความหมายจาก กลุ่มคำที่เฉพาะเจาะจง (เรียกว่า Latent Semantic Analysis - LSA) โดยขึ้นอยู่กับความถี่ของคำ ในแต่ละหัวข้อ เช่น มีคำศัพท์ทางเทคโนโลยี ในบทความเทคโนโลยี ชื่อของนักการเมือง จะพบในข่าวการเมือง ฯลฯ
- เราสามารถสร้างกลุ่ม จากคำทั้งหมดในบทความ แต่เราจะสูญเสีย Connection ที่สำคัญทั้งหมด LSA จะจัดการให้อย่างเหมาะสม นั่นคือสาเหตุ ที่เรียกว่า "Latent Semantic"
- เพื่อให้มีการรักษา Connection ไว้ Singular Value Decomposition (SVD) จะเป็นอีกอันที่ช่วยในภารกิจนี้
แยกประเภทเอกสารโดย Topics
III) Association Rule
ค้นหารูปแบบลำดับในการสั่งซื้อ

ตัวอย่างที่นำไปใช้
- เพื่อคาดการณ์ยอดขายและส่วนลด
- เพื่อวิเคราะห์สินค้าที่ซื้อพร้อมกัน
- เพื่อจัดตำแหน่งผลิตภัณฑ์บนชั้นวาง
- เพื่อวิเคราะห์รูปแบบการท่องเว็บ
- Algorithms ที่นิยม : Apriori, Euclat, FP-growth
- เช่น วิเคราะห์สินค้าในตะกร้า กลยุทธ์การตลาดแบบอัตโนมัติ และ งานอื่น ๆ เมื่อเรามีลำดับของบางอย่าง และต้องการหารูปแบบในนั้น
- นำไปใช้สำหรับ E-commerce Platform เพื่อคาดการณ์ว่า ลูกค้าจะซื้ออะไรในครั้งต่อไป?
- จริง ๆ แล้ว ผู้ค้าปลีกรายใหญ่ สร้างวิธีการเป็นของตนเอง (Proprietary Solution) สำหรับระบบ ที่รู้จักกันในชื่อ - Recommender System
สมมติว่า ลูกค้านำเบียร์ 6 แพ็ค ไปที่จุดชำระเงิน เราควรวางถั่วลิสงระหว่างทางไหม ? มีคนซื้อด้วยกันบ่อยแค่ไหน ? นอกจากเบียร์และถั่วลิสง เรายังสามารถคาดเดาเรื่องอื่น ๆ ได้อีก การเปลี่ยนแปลงสินค้าที่จัดเรียงเล็กน้อย สามารถทำให้กำไรเพิ่มขึ้น ?

ตัวอย่างของ Association Rule

ยังมีต่อ Ep.2
ข้อมูลอ้างอิง Machine Learning for Everyone https://vas3k.com/blog/machine_learning/


