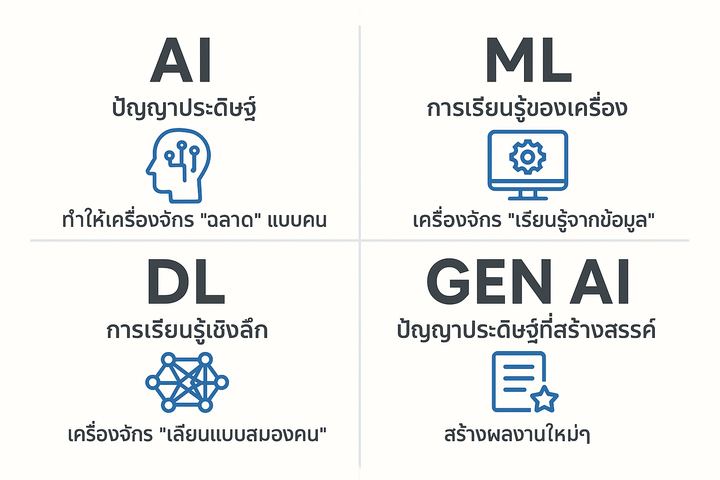
Intro to Machine Learning (Ep.2/2)

อ่าน Ep.1 ได้ที่ https://www.nerd-data.com/intro_ml_ep1/
Part 2 : Reinforcement Learning (RL)
- ในที่สุด เราก็มีบางอย่างที่ใกล้เคียง AI
- ในบทความหลายฉบับ บอกว่า RL คือ สิ่งที่อยู่ระหว่าง Supervised และ Unsupervised แต่จริง ๆ แล้วมันไม่มีอะไรเกี่ยวข้องกันเลย
- RL ถูกใช้ในกรณีที่ เมื่อปัญหาของเราไม่เกี่ยวข้องกับ ข้อมูล แต่เราอยู่ในสิ่งแวดล้อม / สถานการณ์ เช่น โลกของวีดีโอเกมส์ เมืองสำหรับระบบขับรถด้วยตนเอง (Self-driving car)
- เราไม่ได้ใช้ความรู้เกี่ยวกับกฎบนถนนทั้งหมดในโลก สอนระบบขับรถอัตโนมัติด้วยตนเอง
- ไม่ว่าเราจะเก็บรวบรวมข้อมูลเท่าใด เราก็ยังไม่สามารถคาดการณ์สถานการณ์ที่เป็นไปได้ทั้งหมด ดังนั้น เป้าหมาย คือ ลดข้อผิดพลาด ไม่ใช่คาดการณ์ การเคลื่อนที่ของรถ
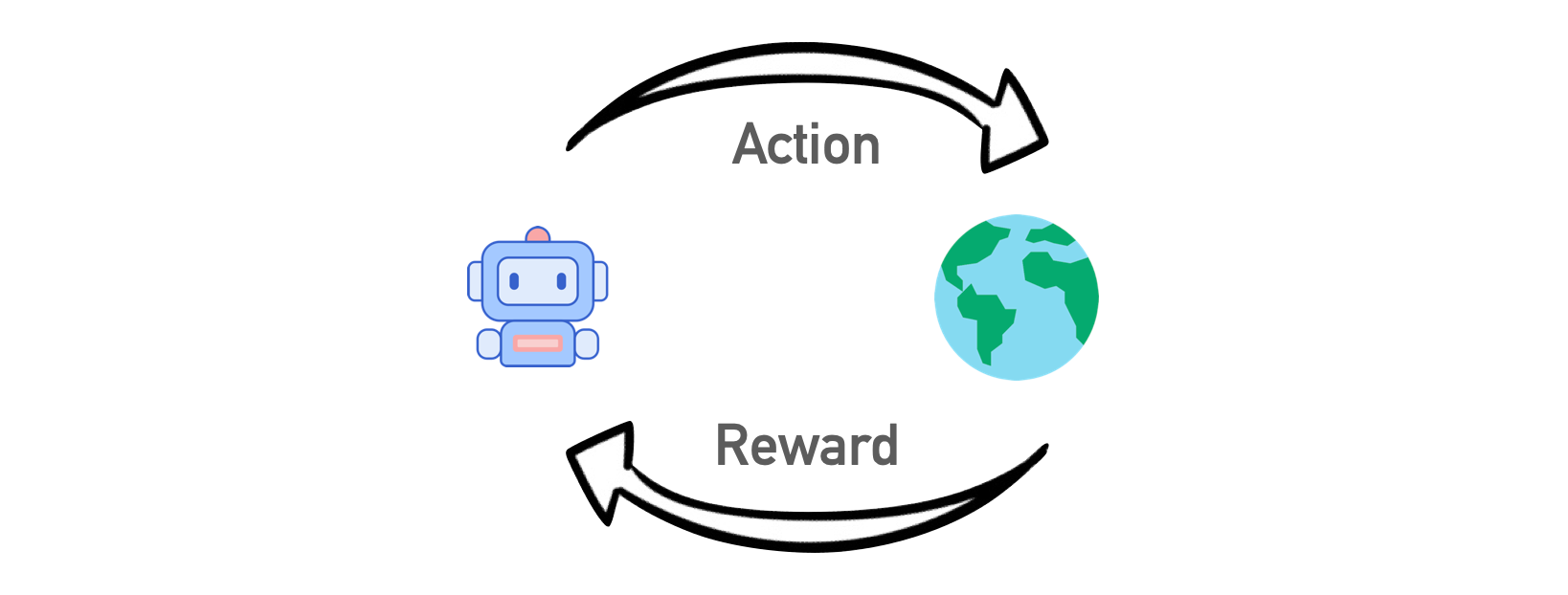
- การอยู่รอดในสภาพแวดล้อมเป็นแนวคิดหลักของ RL โยนหุ่นยนต์ เข้าสู่สภาพแวดล้อมจริง "ลงโทษเมื่อทำผิดพลาด" และ "ให้รางวัลเมื่อทำถูกต้อง"
- วิธีที่มีประสิทธิภาพมากขึ้น คือ สร้างเมืองเสมือนจริง และปล่อยให้รถยนต์ที่ขับขี่ด้วยตนเอง เรียนรู้เทคนิคทั้งหมดที่นั่นก่อน
- มี 2 วิธีการ ที่แตกต่างกัน คือ 1. Model-Based และ 2. Model-Free
- Mode-Based คือ ระบบรถยนต์ ต้องจดจำแผนที่ทั้งหมด เป็นวิธีที่ล้าสมัย เพราะจริง ๆ ไม่สามารถใส่แผนที่ทั้งหมดบนโลกได้
- Model-Free คือ ระบบรถยนต์ ไม่จำเป็นต้องจดจำแผนที่ทั้งหมด แต่พยายามรับมือกับสถานการณ์ โดยพยายามทำให้ได้ Reward มากที่สุด
- Machine เคยเอาชนะ แชมป์โลก Go (หมากล้อม) ความหลากหลายของวิธีการเล่น มากกว่า จำนวน Atom ใน universe นั่นหมายถึง Machine ไม่ได้จดจำวิธีการทั้งหมด แต่มันเลือกวิธีที่ดีสุด ในการเดินหมากแต่ละสถานการณ์
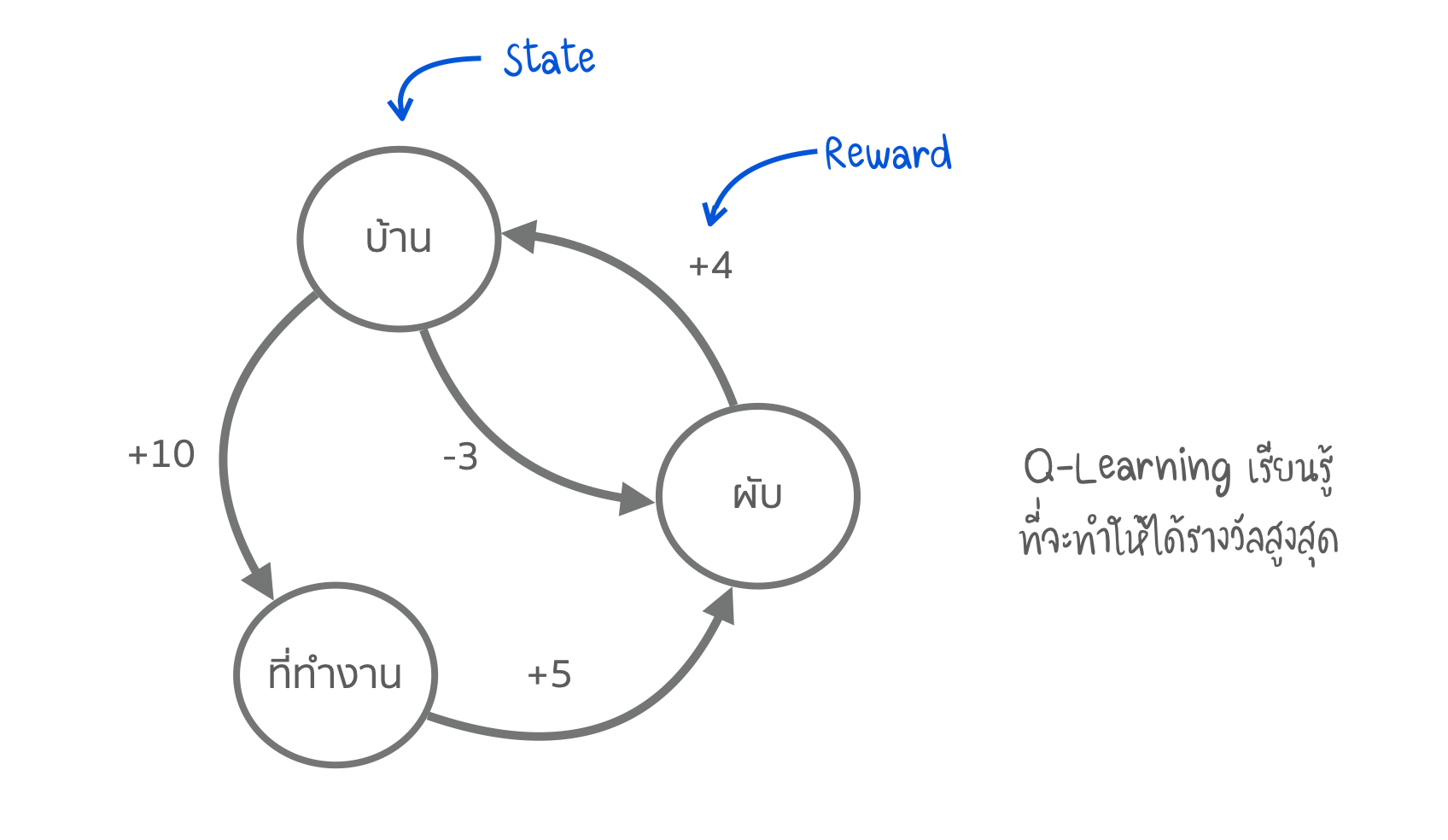
- เบื้องหลัง คือ Q-Learning (และอนุพันธ์ของมัน SARSA & DQN) Q ย่อจาก Quality (คุณภาพ) ซึ่งหุ่นยนต์ เรียนรู้ที่จะปฏิบัติ ให้ได้คุณภาพดีที่สุดในแต่ละสถานการณ์ และในแต่ละการปฏิบัติจะถูกจดจำไว้ คล้าย ๆ กับ กระบวนการของ Markov
(Routine) Markov Process
- Genetic Algorithm เป็นที่นิยมมาก เสมือนการให้หุ่นยนต์จำนวนหนึ่งเข้าไปในสภาพแวดล้อมเดียวกัน และให้มันพยายามที่จะบรรลุเป้าหมายจนกว่าพวกมันจะตาย จากนั้นเราเลือกอันที่ดีที่สุด มีการผสมกัน ให้ยีนกลายพันธุ์ และ Re-run โดยการจำลองสภาพแวดล้อมขึ้นมาอีก หลังจากผ่านไปหลายพันปีเราจะได้ สติปัญญา (Intelligence) ที่ฉลาด และ อาจเป็นวิวัฒนาการที่ดีที่สุด
- Genetic Algorithm เป็นส่วนหนึ่งของ RL
Part 3 : Ensemble Methods
ใช้หลาย ๆ algorithms เพื่อเรียนรู้ และแก้ไขข้อผิดพลาดซึ่งกันและกัน
นำไปใช้กับ
- เหมาะกับวิธีดั้งเดิม (แต่ทำงานได้ดีขึ้น)
- ระบบค้นหา (Search System)
- Computer Vision
- การตรวจจับวัตถุ (Object Detection)
- Algorithms ที่นิยม : Random Forest, Boosting
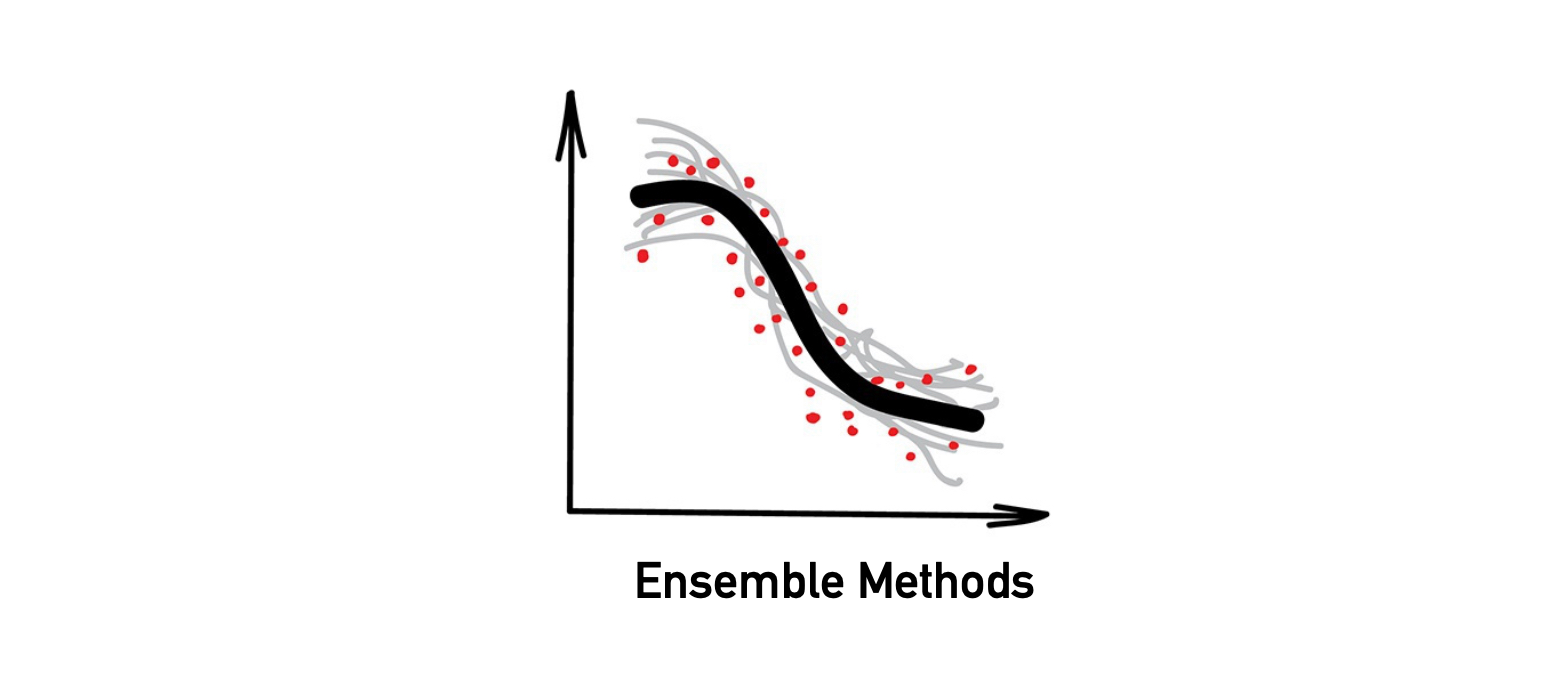
- สำหรับวิธีการปัจจุบันที่ทันสมัย Ensemble และ Neural Network (NN) เป็นสองวิธีหลัก ที่ให้ผลลัพธ์ แม่นยำ และ ใช้อย่างแพร่หลาย
- อย่างไรก็ตาม NN เป็นคำที่อยู่ในความสนใจมากกว่า คำว่า "Boosting" หรือ "Bagging" (Ensemble)
- หากเราใช้ Algorithms ที่ไม่มีประสิทธิภาพ และให้มันแก้ไขข้อผิดพลาดซึ่งกันและกัน (แนวทางของ Ensemble) คุณภาพโดยรวมของระบบจะสูงกว่า Algorithm ที่ดีที่สุดอันเดียว
- ผลลัพธ์จะดียิ่งขึ้น หากเราใช้ Algorithms ซึ่งคาดการณ์ผลลัพธ์ที่แตกต่างกันอย่างมาก เช่น Regression และ Decision Trees โดยที่ Algorithms เหล่านี้ จะ Sensitive มาก แม้มี Outliers เพียงค่าเดียวก็อาจทำให้ Model ผิดพลาดได้
- จริง ๆ แล้ว เราสามารถใช้ Algorithms ใด ๆ เพื่อสร้าง Ensemble แต่ไม่ควรใช้ Algorithms อย่าง Bayes หรือ KNN
มี 3 วิธี ในการสร้าง Ensembles
- Stacking
- Bagging
- Boosting
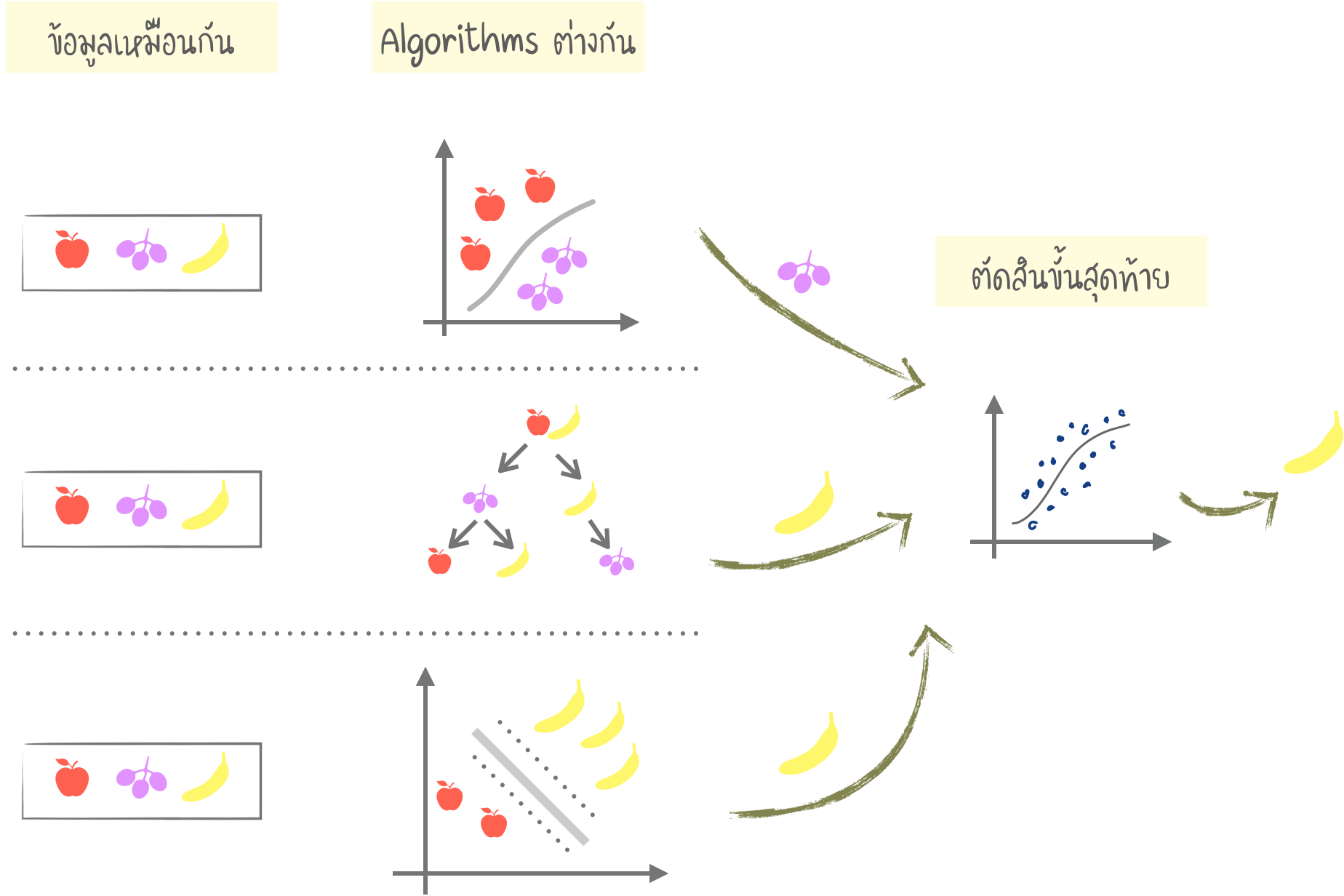
Stacking
- Output ของ Models หลาย ๆ ตัว ถูกส่งผ่านเป็น Input เพื่อการตัดสินใจขั้นสุดท้าย
- การผสม Algorithms "เดียวกัน" กับ ข้อมูล "เดียวกัน" จะไม่มีประโยชน์ ต้อง "แตกต่าง" กัน การเลือก Algorithms นั้นขึ้นอยู่กับเรา แต่อย่างไรก็ตาม ในการตัดสินใจขั้นสุดท้าย Regression คือ ตัวเลือกที่ดี
- "Stacking" ได้รับความนิยมในทางปฏิบัติน้อยกว่า "Bagging" และ "Boosting"
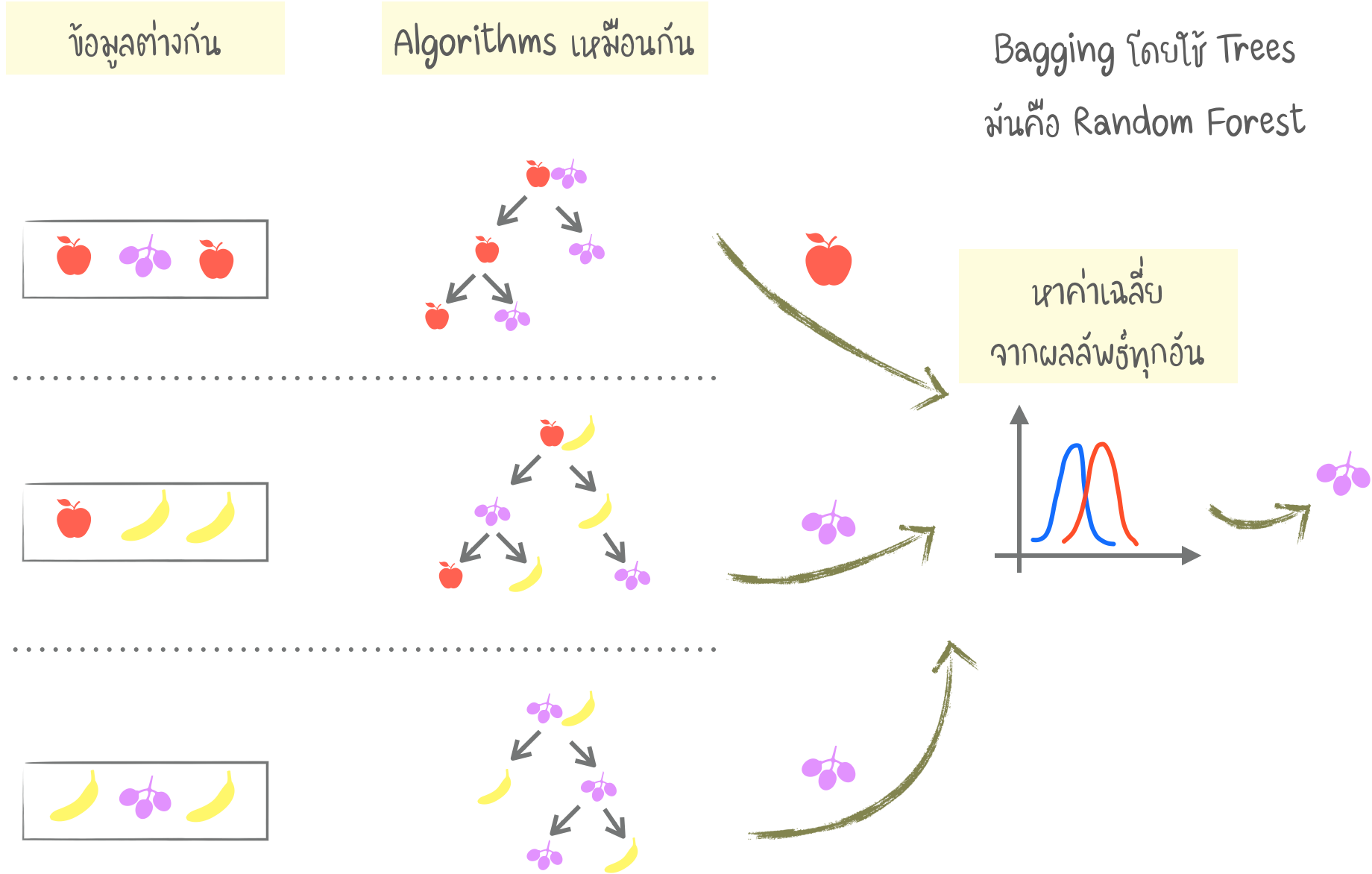
Bagging
- BAGGING ย่อจาก "Bootstrap AGGregatING" วิธีนี้จะใช้ Algorithms เดียวกัน แต่ Train กับข้อมูลชุดย่อย (Subset) ต่าง ๆ กัน
- ข้อมูลชุดย่อย จากการสุ่ม อาจนำมาใช้ซ้ำ เช่น จากชุดเช่น "1-2-3" สามารถเป็นชุดย่อย "2-2-3", "1-2-2", "3-1-2" ฯลฯ เราใช้ชุดข้อมูลใหม่เหล่านี้ ในการ Train Algorithm เดียวกัน ผลลัพธ์ Output ที่ได้หลาย ๆ ครั้ง จะถูกเลือกคำตอบสุดท้ายโดยการ Voting
- Bagging ที่รู้จักกันดี คือ "Random Forest" ซึ่งใช้วิธี Bagging กับ "Decision Tree"
- ในบางงาน หากต้องการประมวลผลแบบ Real time การใช้ Random Forest ที่มีความแม่นยำน้อยกว่า NN เพียงเล็กน้อย อาจมีความเหมาะสมมากกว่า (เพราะทำงานได้เร็วกว่า)
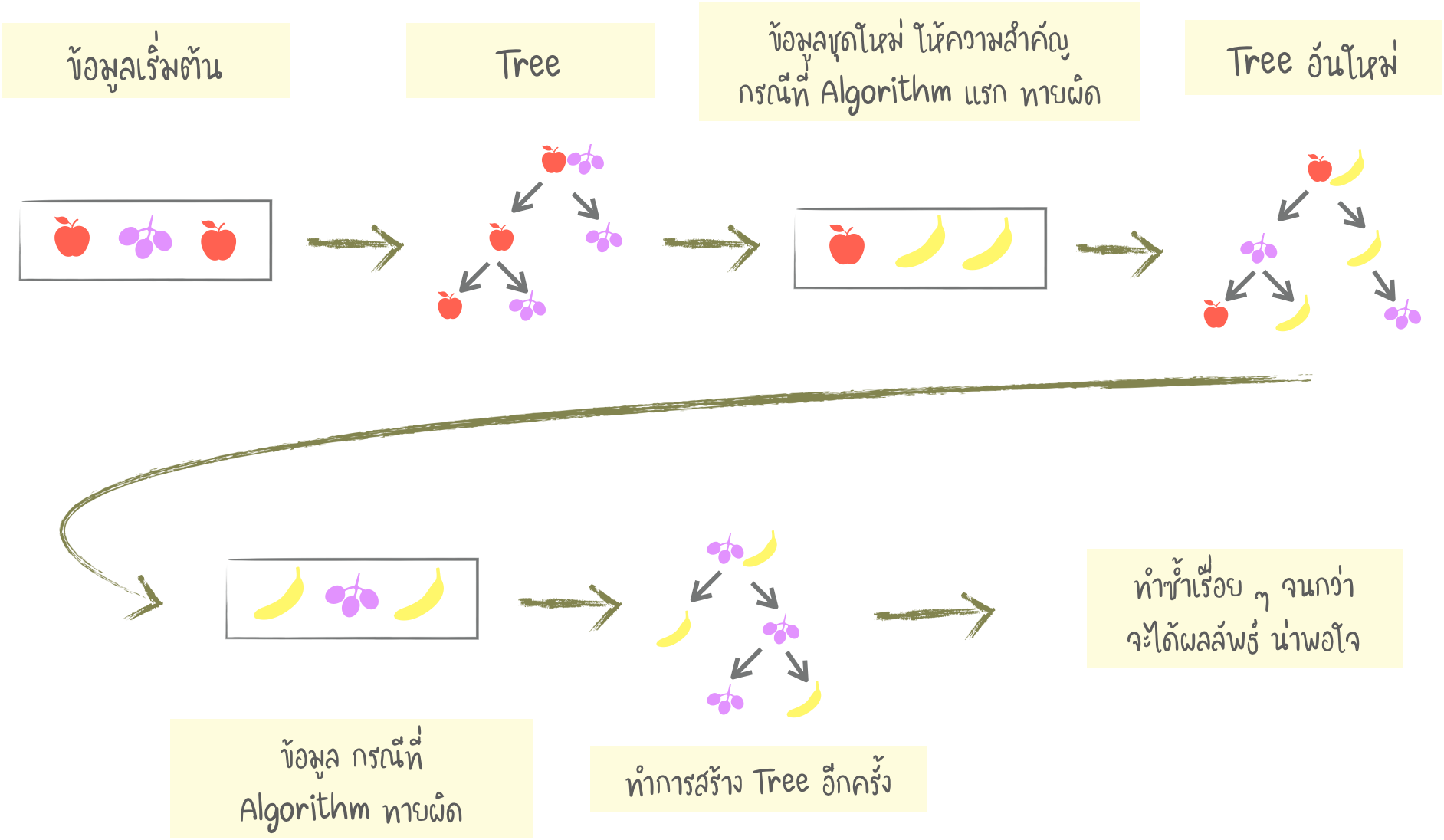
Boosting
- Boosting Algorithm จะถูก Train ทีละลำดับ ในการทำงานลำดับต่อไป จะให้ความสนใจกับข้อมูลส่วนที่ผิดพลาดก่อนหน้านี้ ทำซ้ำไปเรื่อย ๆ จนกว่าผลลัพธ์เป็นที่น่าพอใจ
- เช่นเดียวกับ Bagging เราใช้ข้อมูลชุดย่อย (แต่ไม่ใช่การสร้างแบบสุ่ม)
- ในแต่ละข้อมูลชุดย่อย ข้อมูลที่ Algorithm ก่อนหน้าไม่สามารถดำเนินการได้ จะถูกนำไป Train ด้วย Algorithm ใหม่ เพื่อ เรียนรู้ / แก้ไข ข้อผิดพลาดของก่อนหน้านี้
- ข้อดี คือ ทำให้ความถูกต้องสูงขึ้น ข้อเสีย คือ ไม่ใช่การทำงานแบบขนาน (Parallel) ทำให้ทำงานช้ากว่า Stacking, Bagging แต่ยังเร็วกว่า เมื่อเทียบกับ NN
- ปัจจุบันมีเครื่องมือ Boosting ที่นิยม 3 ตัว คือ CatBoost, LightGBM, XGBoost
Note : CatBoost ย่อจาก Category Boosting
Part 4 : Neural Network (NN) & Deep Learning (DL)
ตัวอย่างที่นำมาใช้
- ใช้แทน Algorithms ทั้งหมดข้างต้น
- การระบุวัตถุ (Object Identification) บนภาพและวิดีโอ
- การจำแนกเสียง / การสังเคราะห์เสียง
- การประมวลผลภาพ
- การถ่ายโอนรูปแบบ (Style Transfer)
- เครื่องแปลภาษา
- สถาปัตยกรรมที่นิยม : Perceptron, Convolutional Neuron Network (CNN), Recurrent Neuron Network (RNN), Auto-encoders
- NN นั้นเป็นชุดของ เซลล์ประสาท (Neurons) ที่เชื่อมต่อ (Connect) ระหว่างกัน
- Neurons เป็นฟังก์ชั่น ที่มี Input จำนวนมาก แต่ Output เพียงหนึ่งเดียว หน้าที่ของมัน คือ การรับข้อมูล Input ทั้งหมด ดำเนินการผ่านฟังก์ชัน และส่งผลลัพธ์ไปยัง Output
- ตัวอย่างเซลล์ประสาทอย่างง่าย เช่น ถ้าผลรวมตัวเลขทั้งหมดจาก Input มีค่ามากกว่า N ให้ผลลัพธ์ "เป็น 1" นอกนั้น ผลลัพธ์ "เป็น 0"
- การเชื่อมต่อ เหมือนเป็นช่องทางระหว่างเซลล์ประสาท เชื่อมต่อ Output ของเซลล์ประสาทหนึ่งกับ Input ของอีกเซลล์หนึ่ง เพื่อสามารถส่งตัวเลขต่อ ๆ กันได้
- แต่ละการเชื่อมต่อมีพารามิเตอร์ตัวหนึ่ง คือ น้ำหนัก (Weight) เป็นเหมือนความแรงของการเชื่อมต่อสัญญาณ เมื่อเลข 10 ผ่านการเชื่อมต่อที่มีน้ำหนัก 0.5 มันจะกลายเป็น 5
- การที่ Network เรียนรู้ คือ น้ำหนักจะถูกปรับ ในระหว่างการ Train Model
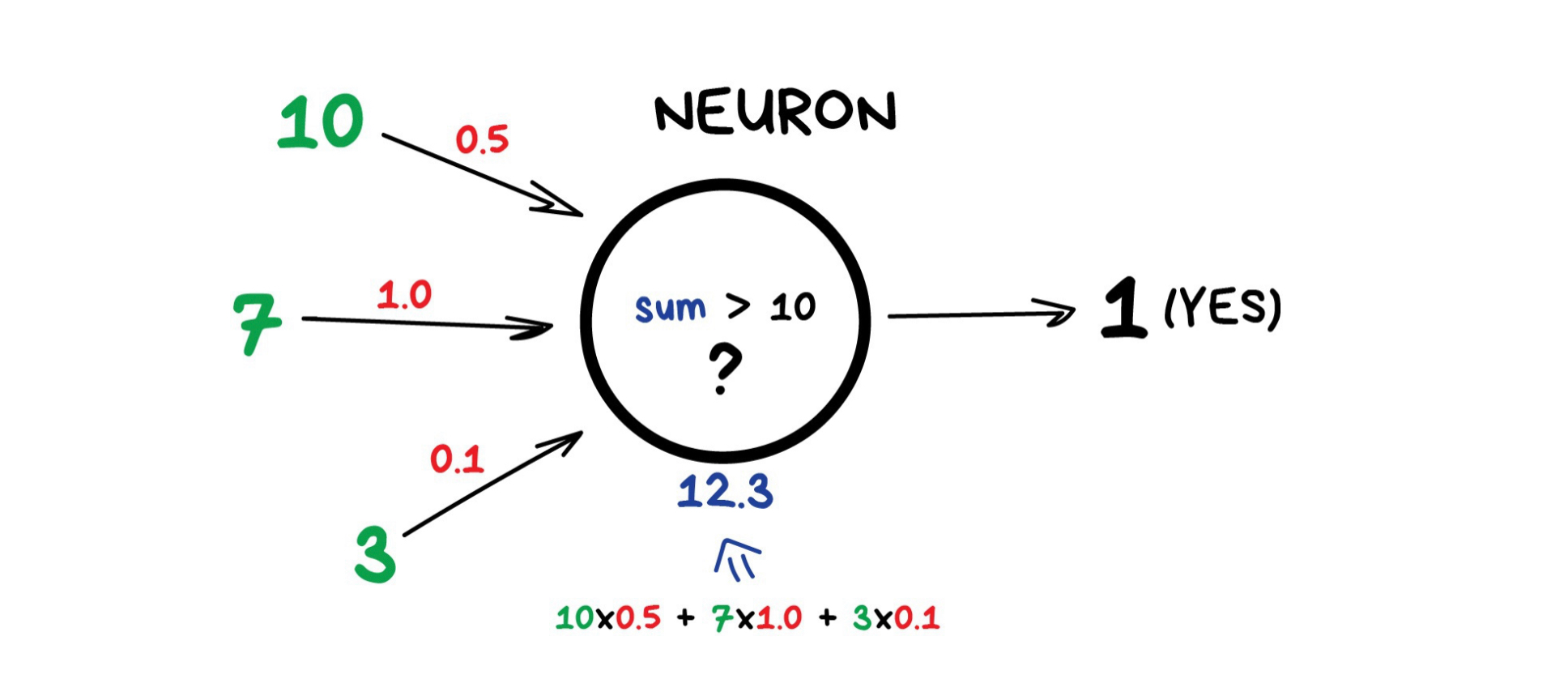
- เงื่อนไขของ Network คือ Neurons จะถูกเชื่อมโยงด้วยลำดับ Layers (ไม่ใช่การสุ่ม)
- ภายใน Layer เดียวกันจะไม่เชื่อมต่อกัน แต่เชื่อมต่อกับ Neurons ของ Layers ถัดไปและก่อนหน้า ข้อมูลใน Network จะไปในทิศทางเดียว จาก Input ของ Layer แรกไปยัง Output สุดท้าย
- หากเรากำหนด จำนวน Layers และ weight ที่เหมาะสม โดยใช้ Input ภาพเลข 4 ที่เขียนด้วยลายมือ
- Pixel สีดำ จะทำการ Activate ใช้งาน Neurons ที่เกี่ยวข้องต่อไปเรื่อย ๆ จนกระทั่งให้ผลลัพธ์ Output เป็น 4 อย่างถูกต้อง
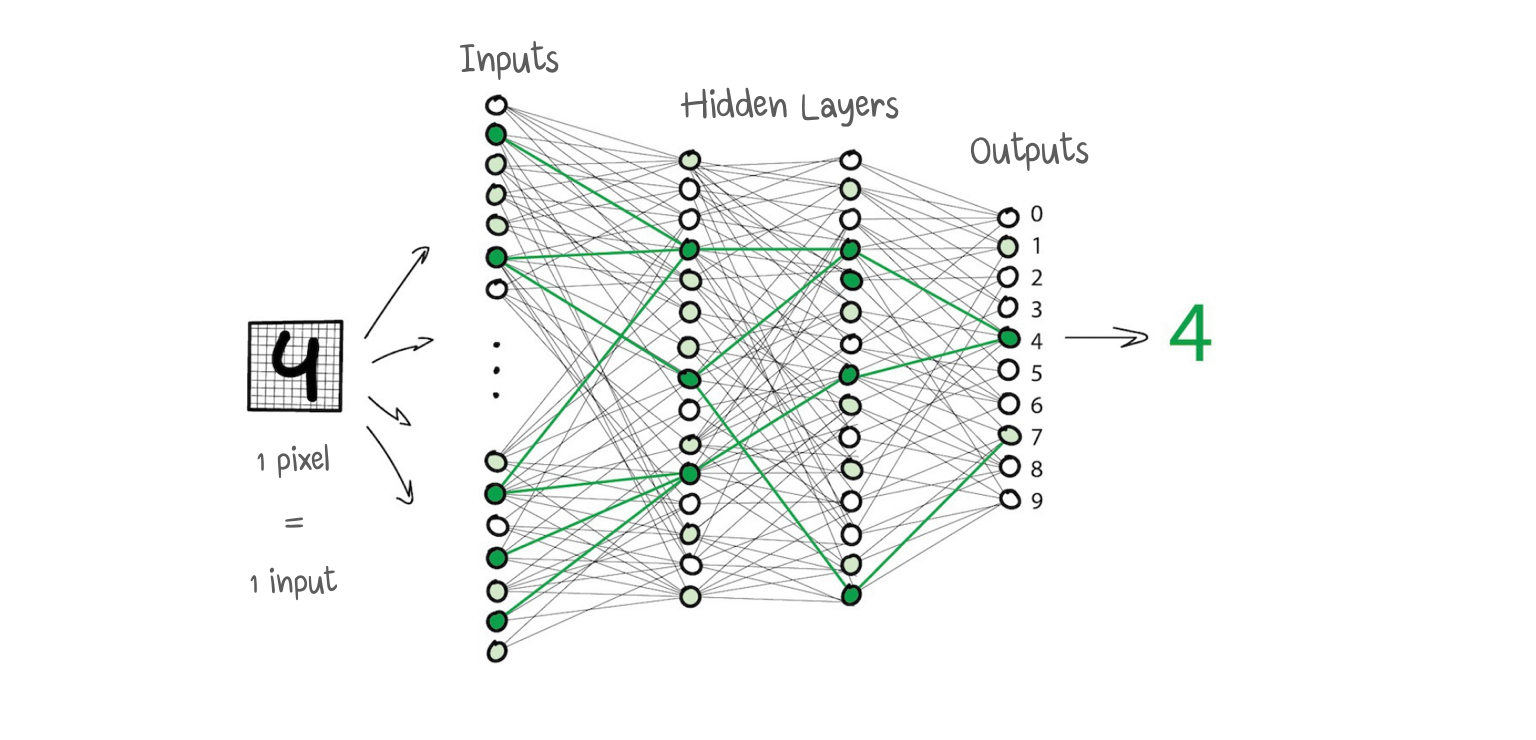
- ในการเขียน Program ไม่มีใครเขียน Neurons ที่เชื่อมต่อกัน แต่จะคำนวณบนพื้นฐานของ Matrices
- Network ที่มีหลาย Layers และมีการเชื่อมต่อระหว่าง Neurons ทุกตัวเรียกว่า (Multi Layer) Perceptron - MLP ถือเป็นสถาปัตยกรรมที่ง่ายที่สุด แต่ไม่ค่อยนำไปใช้งานจริง
- หลังจากที่เราสร้าง Network เราจะกำหนดวิธีการที่เหมาะสมเพื่อให้ Neurons ตอบสนองอย่างถูกต้องกับสัญญาณ Input ดังนั้น เราต้องมีข้อมูลตัวอย่าง ของ Input และ Output ที่เหมาะสม
- ในช่วงเริ่มต้น Weights ทั้งหมด จะถูกกำหนดแบบสุ่ม หลังจากที่ใส่ Input ตัวเลขมันจะให้ผลลัพธ์แบบสุ่มเพราะ Weights ยังไม่ถูกต้อง และเราเปรียบเทียบว่าผลลัพธ์นี้แตกต่างจากสิ่งที่ถูกต้องมากแค่ไหน และกลับไปบอกทุก ๆ Neurons ว่า ทำงานได้ ดี /แย่ แค่ไหน?
- หลังจากนับแสน ๆ รอบของ “infer-check-punish” เราหวังว่า Weights จะได้รับการแก้ไข / ปรับ ให้เหมาะสม วิธีนี้ เรียกว่า Back-propagation
- NN ที่ผ่านการ train มาอย่างดี สามารถใช้แทน Algorithms ใด ๆ (และทำงานได้แม่นยำยิ่งขึ้น) ทำให้ได้รับความนิยม
- ในที่สุด เราก็มีสถาปัตยกรรมของสมองมนุษย์ การรวบรวม Layers จำนวนมากและสอนพวกมันเกี่ยวกับข้อมูลที่เป็นไปได้ที่พวกมันคาดหวัง จากนั้น ก็เกิด AI Winter (AI ไม่ได้รับความสนใจ) เนื่องจาก Network ที่มี Layers จำนวนมาก ไม่มีพลังในการคำนวณที่เป็นไปได้ในเวลานั้น ทุกวันนี้ PC ที่มี GeForce ยังมีประสิทธิภาพสูงกว่า Data Center ในช่วงเวลานั้น
- แต่ ในปี 2012 NN ได้รับชัยชนะในการแข่งขัน ImageNet และเป็นที่รู้จักไปทั่วโลก
- ความแตกต่างของ DL กับ NN ดั้งเดิม คือ DL เป็นวิธี Train แบบใหม่ที่สามารถรองรับ Networks ที่ใหญ่กว่าได้
- ในทางปฏิบัติ Libraries ยอดนิยมของ DL คือ Keras, TensorFlow & PyTorch
ส่วนถัดไป มี DL 2 ประเภทหลัก ที่จะอธิบาย คือ I) CNN และ II) RNN
CNN (Convolutional Neuron Network)
- CNN ถูกนำไปใช้ เช่น ค้นหาวัตถุบนรูปภาพ / วิดีโอ ใช้ในการจำแนกใบหน้า การถ่ายโอนสไตล์ การสร้าง / ปรับปรุงภาพ การสร้าง Effects เช่น ภาพช้า และ การปรับปรุงคุณภาพของภาพ
- ทุกวันนี้ CNN ถูกนำมาใช้กับ ข้อมูลรูปภาพ / วิดีโอ แม้กระทั่งใน iPhone ของเรา
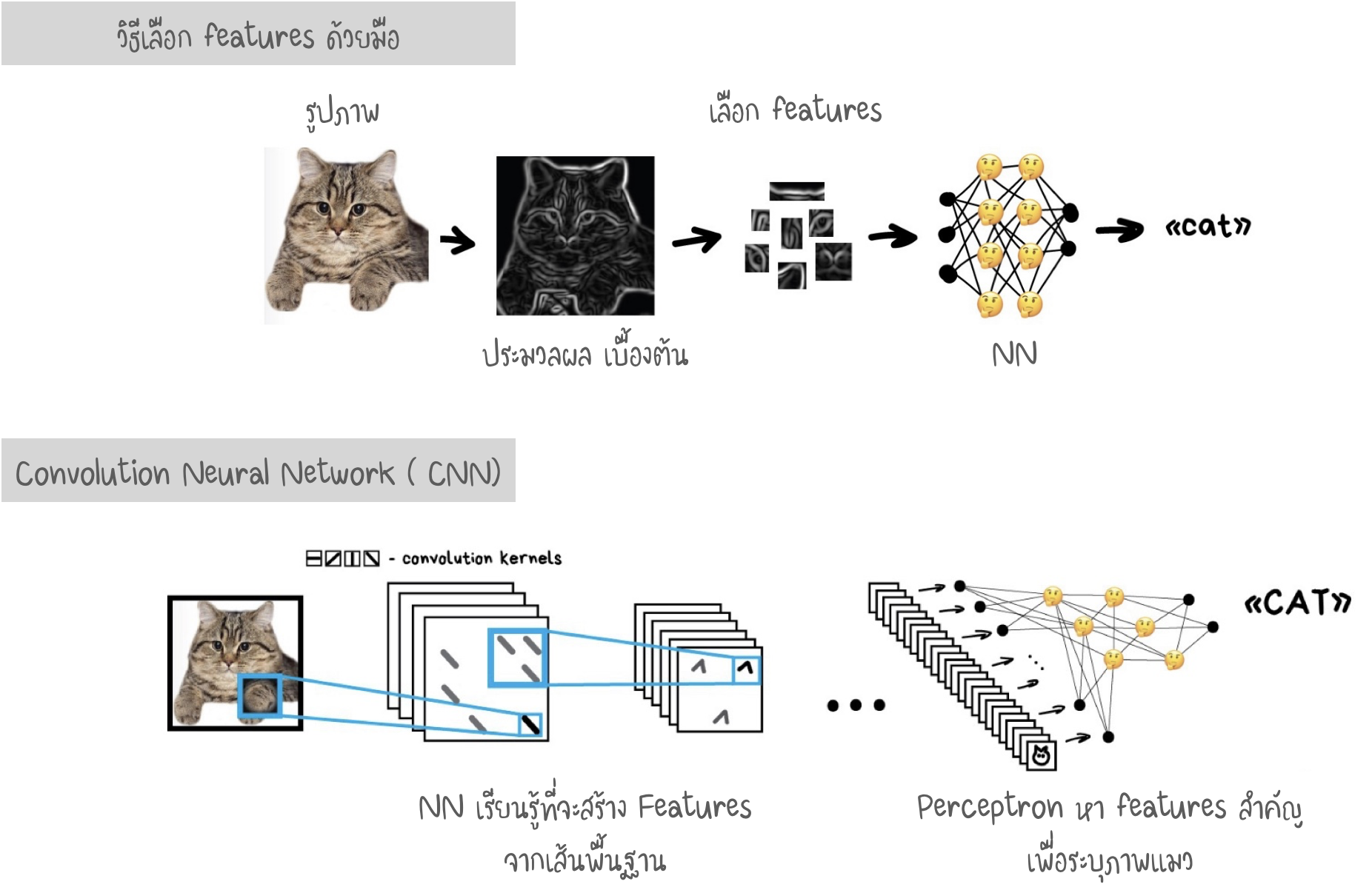
- การทำงานกับรูปภาพ ความยากคือการดึง Features ออกมา หากรูปภาพ ต้องมีการกำหนด Features ด้วยมือ (Handcrafting Features) เพื่อนำไปใช้ Train เช่น นี่คือ ส่วน หู / หาง แมว

- การกำหนด Features ด้วยมือ อาจมีปัญหามากมาย
- หาก “หูแมว” ตกลงมา หรือ มัน “หันหลัง” ให้กล้อง : เราจะมีปัญหา NN จะไม่เห็นอะไรเลย
- หากให้เราลองกำหนด 10 Features ของแมวที่แตกต่างจากสัตว์อื่น คงทำไม่ได้ แต่ หากเราเห็นแค่เงาสีดำพุ่งผ่าน ตอนกลางคืน - เราจะบอกได้ว่า คือ แมว เนื่องจากมนุษย์ไม่ได้ดูเพียง รูปแบบหู จำนวนขา และ Features ที่แตกต่างกัน ดังนั้นจึงไม่สามารถอธิบายได้กับ Machine
- Machine จำเป็นต้องเรียนรู้ Features ต่าง ๆ ด้วยตัวเอง ดังนี้ : แบ่งภาพทั้งหมดออกเป็นบล็อกขนาด 8 x 8 pixels และ กำหนดประเภทของเส้นที่โดดเด่น เช่น แนวนอน [-] แนวตั้ง [|] หรือ แนวทแยงมุม [/]
- Output จะเป็นตารางที่มีเส้นหลายแบบ แสดงถึงขอบวัตถุบนภาพ ซึ่งเป็น features ที่ง่ายที่สุด และ เราเราสามารถสร้างบล็อก 8 x 8 ได้ไปอีกเรื่อย ๆ เพื่อเพิ่มความซับซ้อนของ features
- การดำเนินการนี้เรียกว่า Convolution สามารถถูกนำไปใช้ใน Layers ของ NN
RNN (Recurrent Neural Network)
- สถาปัตยกรรม ที่นิยมเป็นอันดับ 2 คือ RNN ใช้ใน การแปลภาษาด้วยเครื่อง (Machine Translation) การจำแนกเสียง (Voice Recognition) การสังเคราะห์เสียง (Voice Synthesis) เช่น Amazon Alexa หรือ Google Assistant สามารถพูดได้อย่างชัดเจน (ด้วยสำเนียงที่ถูกต้อง)
- ด้วย Neural Net ทำให้ Voice Assistant ในปัจจุบันกำลังพยายามพูดทั้งวลี / ประโยค แทนที่จะเป็นทีละตัว เหมือนเมื่อก่อน เราสามารถนำข้อความที่เปล่งเสียงออกมา Train NN เพื่อสร้างเสียงที่ใกล้เคียงกับคำพูดดั้งเดิม
- กล่าวคือ เราใช้ข้อความเป็น Input และ เสียงของมันเป็น Output ที่ต้องการ
- เราสามารถ train Perceptron เพื่อสร้างเสียงที่เป็นเอกลักษณ์เหล่านี้ แต่จะจำคำตอบก่อนหน้าได้อย่างไร? ดังนั้น การเพิ่มหน่วยความจำให้กับแต่ละ Neuron เพื่อใช้เป็นข้อมูลเพิ่มเติม ในการทำงานครั้งต่อไป เช่น Neuron รู้ว่ามีเสียงสระ ก็บอกได้ว่า เสียงต่อไปควรจะเป็นอะไรดี
- นี่คือวิธีของ RNNs
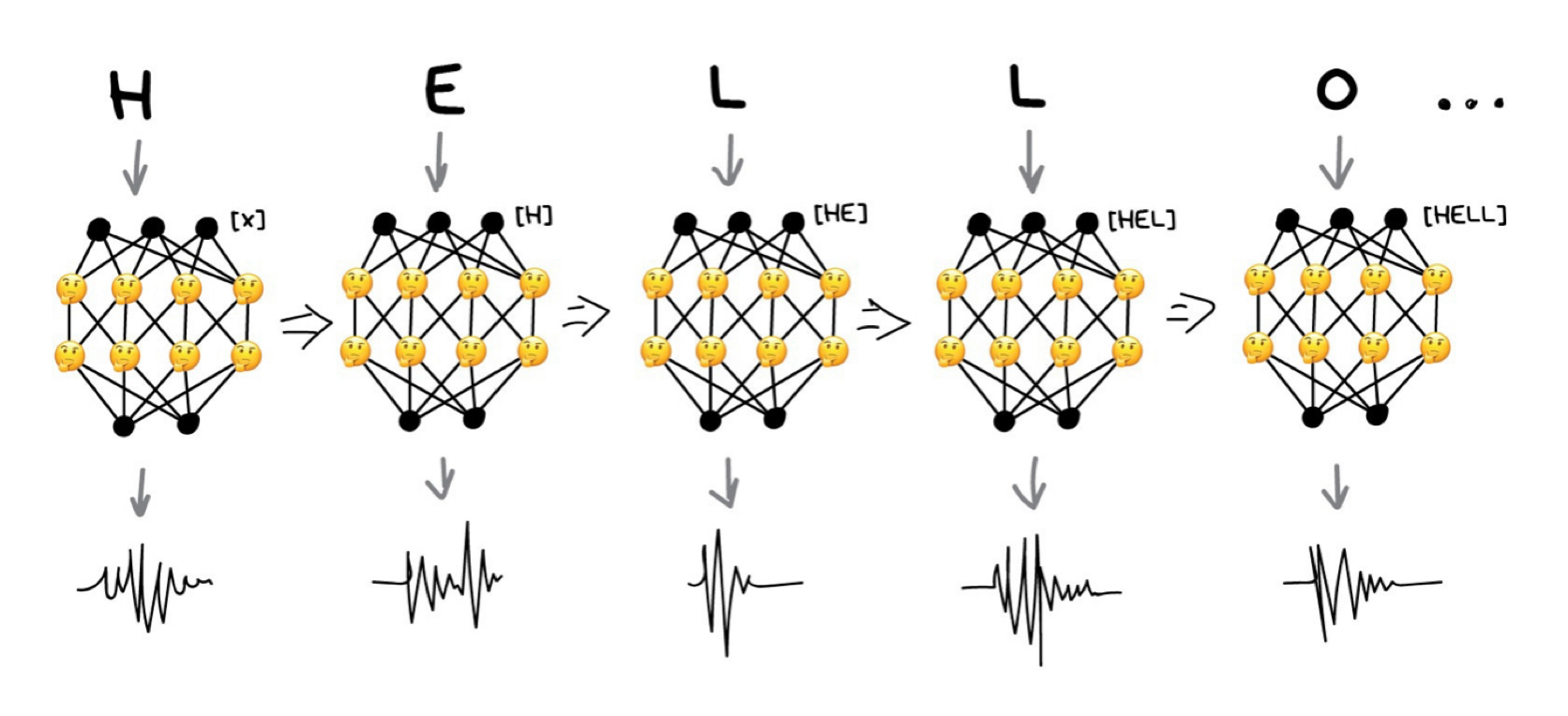
- ปัญหาอันหนึ่ง คือ เมื่อ Neurons จดจำผลลัพธ์ทั้งหมด ที่ผ่านมา จำนวน Connection ใน Networks จะมีขนาดใหญ่มาก จนทำให้ไม่สามารถปรับ Weight ได้ทัน
- เมื่อ NN ไม่สามารถลืมของเก่า มันก็ไม่สามารถเรียนรู้สิ่งใหม่ (คล้าย ๆ กับคน)
- วิธีแก้ในตอนแรก คือ ให้ Neurons จดจำแค่เพียง ผลลัพธ์ล่าสุดไม่เกิน 5 รายการ
- แต่วิธีที่ดีกว่า คือ การใช้เซลล์พิเศษ (คล้ายกับหน่วยความจำ) แต่ละเซลล์สามารถบันทึกหมายเลข (Read / Reset ได้) เรียกว่า Long and Short Term Memory (LSTM)
- ดังนั้น Neurons สามารถตั้งค่าสถานะในเซลล์นั้น เช่น "มันเป็นพยัญชนะในคำ ครั้งต่อไป ให้ใช้กฎการออกเสียงที่แตกต่างกัน" เมื่อไม่ต้องการตั้งค่าสถานะในเซลล์ จะถูก Reset โดยเหลือเพียง Connection แบบ "Long term" ของ Perceptron เท่านั้น กล่าวคือ NN ได้รับการ Train ไม่เพียงแค่เรียนรู้ Weight แต่ยังสามารถตั้งค่าสถานะในเซลล์ได้
ข้อสรุปสงครามระหว่าง "Machine"
- คำถามที่ว่า "เมื่อ Machine ฉลาดกว่าเรา และทำให้ทุกคนเป็นทาส?"
- จริง ๆ แล้ว คำว่า "ฉลาดกว่า" เป็นสิ่งที่วัดได้ยาก แม้เราจะคิดว่ามนุษย์ ฉลาดสุด ในบรรดาสัตว์ แต่ ในบางเรื่องมนุษย์ ไม่สามารถเอาชนะสัตว์ได้ เช่น กระรอกสามารถจดจำสถานที่ ที่ซ่อนอยู่นับพันด้วยถั่ว
- ดังนั้นความฉลาดเป็นชุดของทักษะที่แตกต่าง ไม่ใช่การวัดเพียงอย่างเดียว
- สิ่งที่น่าสนใจ คือ เราเชื่อว่าสมองมนุษย์นั้นจำกัด แต่ความก้าวหน้าทางเทคโนโลยีถูกพัฒนาไปแบบก้าวกระโดด
- หากต้องการคูณเลข 1,680 กับ 950 จะไม่มีใครคูณในใจ ถ้าให้เครื่องคิดเลข เราจะทำได้ใน 2 วินาที หมายความว่า เครื่องคิดเลขเพิ่งขยายขีดความสามารถของสมองเรา ใช่หรือไม่?
- ดังนั้น เราจะขยายมันต่อด้วยเครื่องอื่น ได้หรือไม่? เช่น การใช้บันทึกย่อในโทรศัพท์ เพื่อที่เราไม่ต้องจำข้อมูล ก็เหมือนเรากำลังขยายขีดความสามารถของสมองด้วยเครื่องมือนั่นเอง
ข้อมูลอ้างอิง Machine Learning for Everyone https://vas3k.com/blog/machine_learning/