Evaluation Metrics for Classification Model

การประเมิน (Evaluate) Model เป็นส่วนสำคัญในการสร้าง Machine Learning models ที่มีประสิทธิภาพ
- ในการประเมินการ Classification ตัวชี้วัดที่ใช้บ่อยที่สุด ควรจะเป็น “Accuracy”
- เมื่อ Model มี Accuracy = 99% เราเชื่อว่า มันน่าจะดี แต่มันไม่จริงเสมอไป และในบางสถานการณ์อาจทำให้เข้าใจผิดได้
ใน Blog นี้ จะอธิบาย 4 เรื่อง ดังนี้
- Confusion Matrix สำหรับ Binary Classification
- Metrics สำหรับประเมินการ Classification : Accuracy, Recall, Precision และ F1- Score
- ข้อแตกต่างระหว่าง Recall และ Precision ในกรณีต่างๆ
- Decision Thresholds และ Receiver Operating Characteristic (ROC) curve
ปัญหา Binary Classification การทำนายมีเพียง 2 Classes คือ "ใช่" หรือ "ไม่ใช่"
- เช่น การจำแนก เพื่อทำนายว่ารูปภาพเป็น สุนัข หรือ แมว ใน Supervised Learning เราจะ Train model จากข้อมูล Train ขึ้นมาก่อน จากนั้น ทดสอบ Model กับข้อมูล Test
- เมื่อ Model มีการทำนายจากข้อมูล X_test ได้ผลทำนายเป็น y_test เราจะเปรียบเทียบกับค่า y_actual (Label ที่ถูกต้อง)
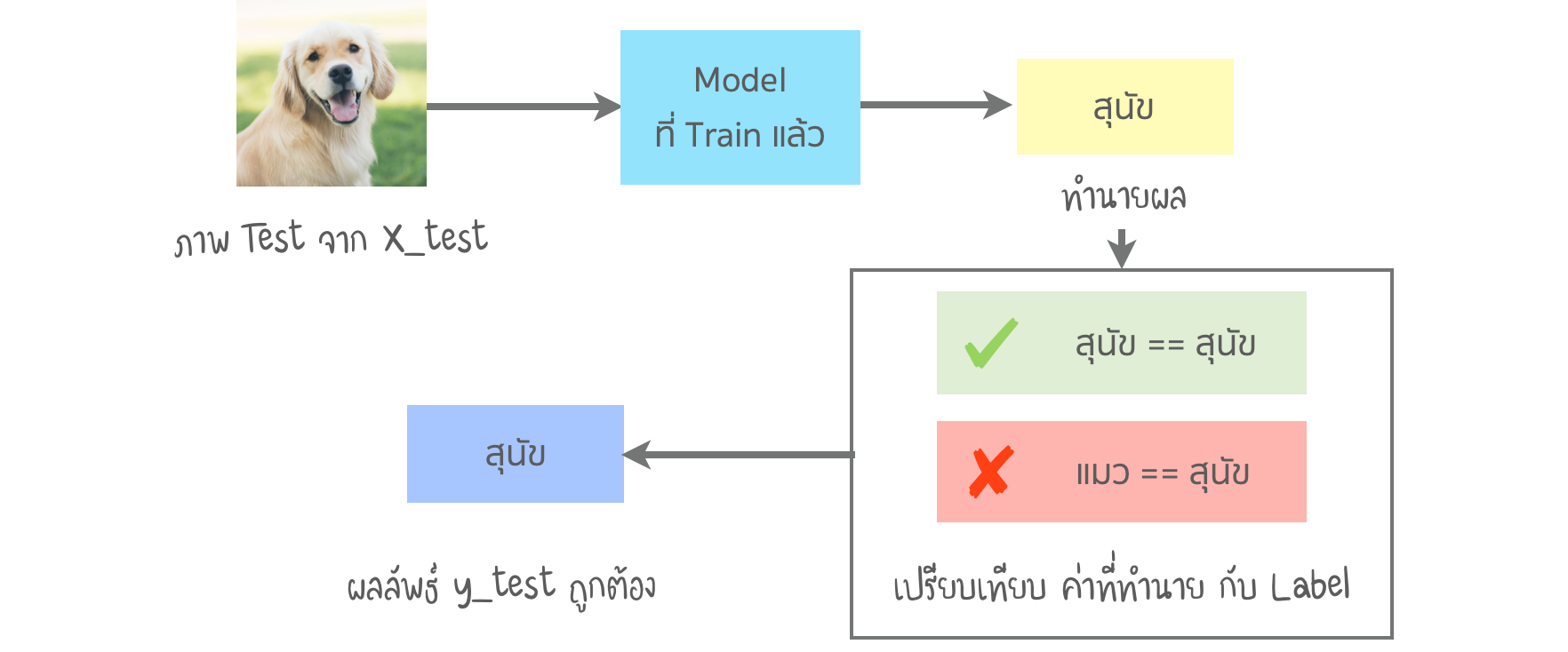
- หากใส่ภาพสุนัขเข้าไป ใน Model ที่ผ่านการ Train แล้ว Model ทำนายว่าเป็น สุนัข เมื่อนำไปเปรียบเทียบ Label ผลลัพธ์ คือ ถูกต้อง หากทำนายว่าเป็น แมว ผลลัพธ์นี้ จะถือว่า ไม่ถูกต้อง
- ทำกับภาพทั้งหมดในข้อมูล X_test ท้ายที่สุด เราจะมีจำนวนการจับคู่ที่ ถูกต้อง / ไม่ถูกต้อง ในการประเมินลักษณะนี้ ค่า ถูกต้อง / ไม่ถูกต้อง ถือว่ามีน้ำหนักเท่ากัน ดังนั้น การวัดโดยใช้ Metrics เดียว (Accuracy) จะไม่บอกเรื่องราวทั้งหมด
- ดังที่ได้กล่าวมา Accuracy เป็นหนึ่งในตัวชี้วัดการประเมินทั่วไป คำนวณจาก
“จำนวนการทำนายถูก ทั้งหมด” หารด้วย “จำนวนการทำนาย ทั้งหมด”
- แต่ในบทความนี้ จะพูดถึง Metrics อื่นๆ ด้วย
ข้อมูลส่วนใหญ่ ไม่สมดุล
- ค่า Accuracy จะมีประสิทธิภาพ เมื่อ Target มี Class ที่สมดุล แต่จะไม่มีประสิทธิภาพ เมื่อ Target มี Class ที่ไม่สมดุล เช่น หากมีจำนวน สุนัข 99 ภาพ และ แมวเพียง 1 ภาพ ในข้อมูล Train ของเรา Model นั้น ทำนาย สุนัข เพียงอย่างเดียว จะได้ ค่า Accuracy ที่ 99% แล้ว
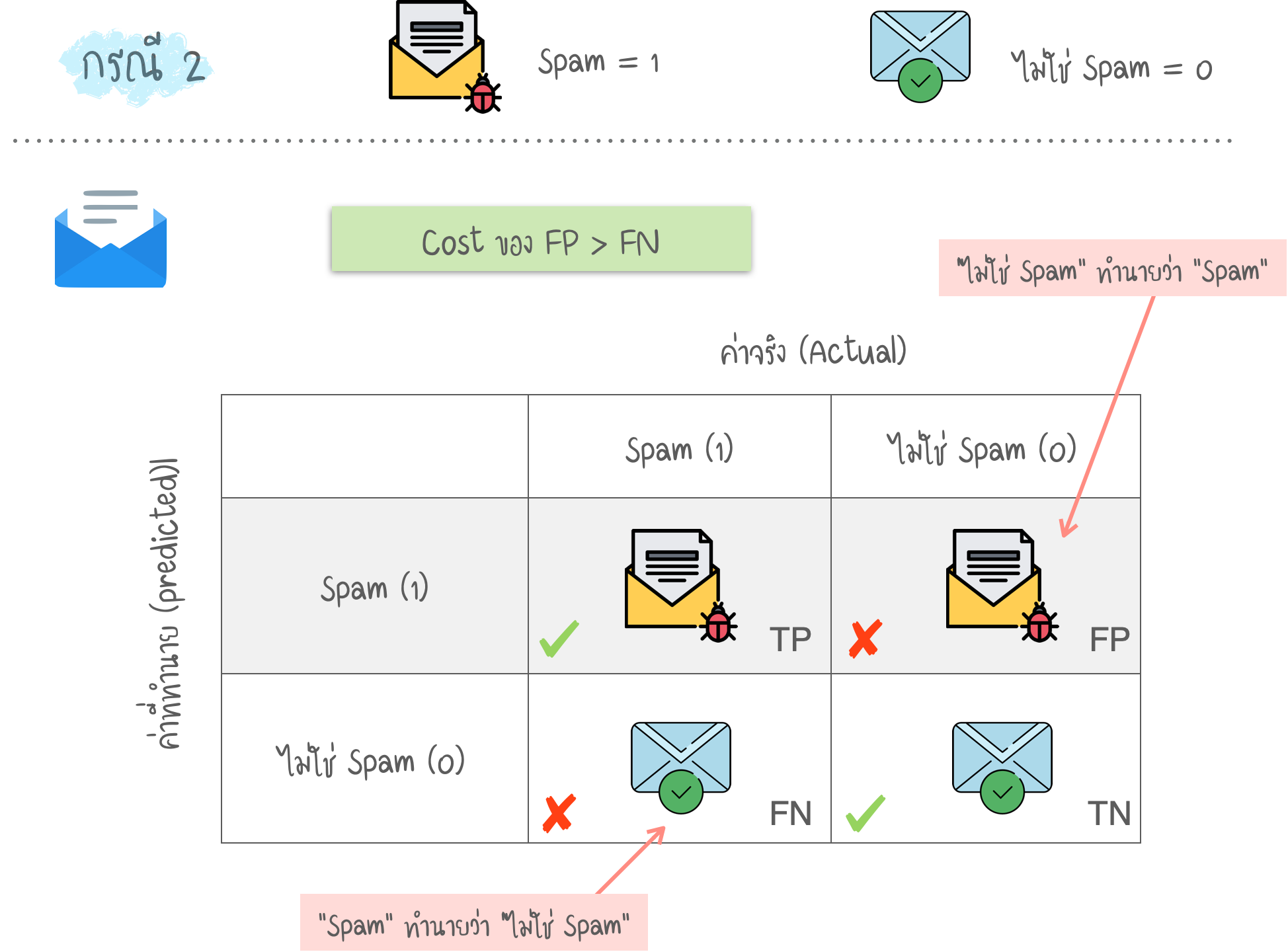
- ในความเป็นจริง ข้อมูลส่วนใหญ่ก็ ไม่สมดุล เช่น Spam Mail, การฉ้อโกง (Fraud) บัตรเครดิต และ การวินิจฉัยทางการแพทย์ ดังนั้น หากต้องการเห็นภาพรวมของการประเมิน Model ทั้งหมด จึงควรพิจารณาตัวชี้วัดอื่นๆ ด้วย เช่น Recall และ Precision
Confusion Matrix
- ประสิทธิภาพของ Classification Model จะขึ้นอยู่กับ จำนวนที่ Model ทำนาย ถูกต้อง และ ไม่ถูกต้อง
- Confusion Matrix ทำให้สามารถเห็น Insights ที่ลึกมากยิ่งขึ้น ไม่เพียง แต่ประสิทธิภาพของ Model แต่รวมไปถึง การทำนาย ว่า Class ใด ถูกต้อง / ไม่ถูกต้อง และ ประเภทของความผิดพลาดที่เกิดขึ้น
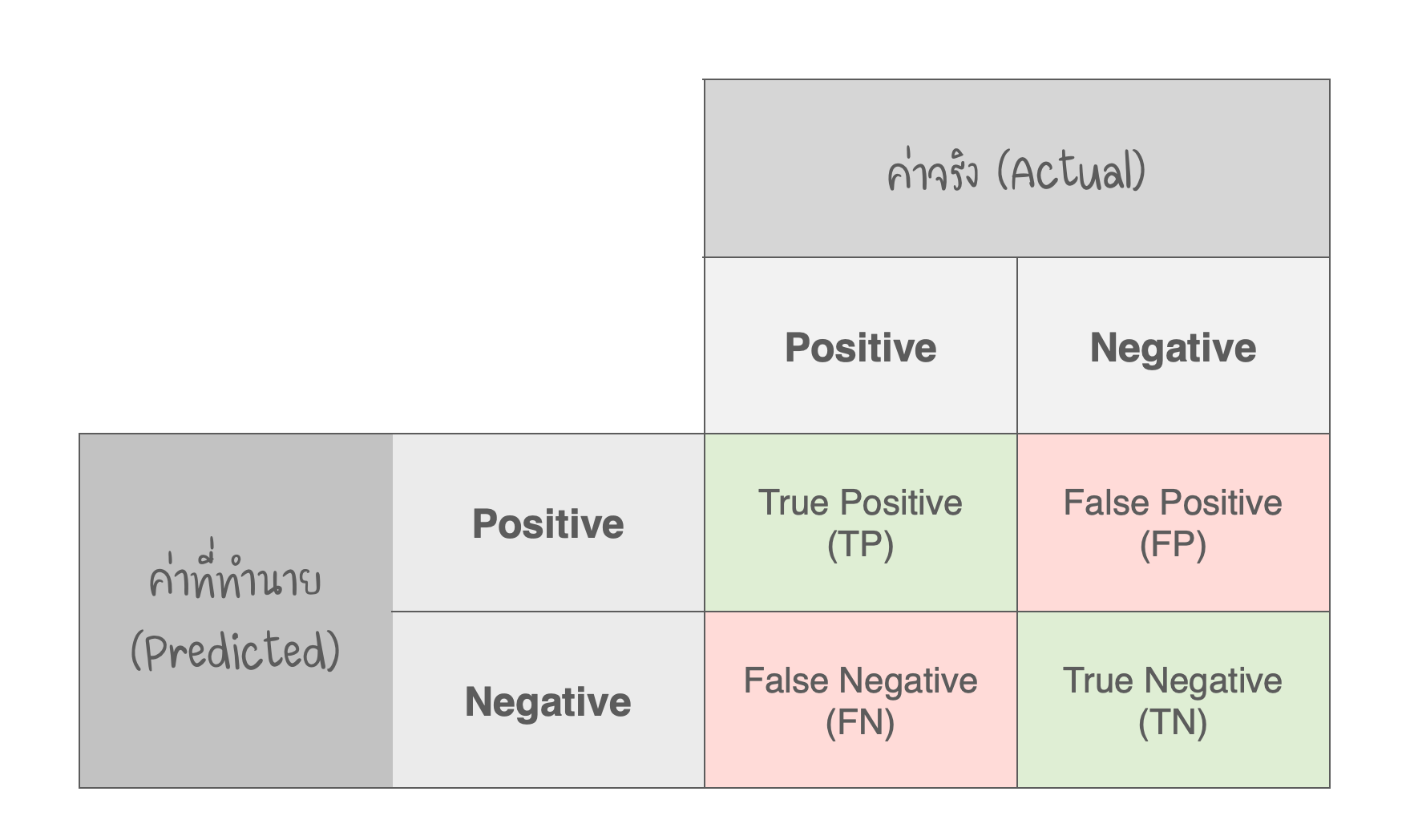
- ใน Confusion matrix มีการคำนวณตัวชี้วัดการ Classification 4 แบบ ดังนี้
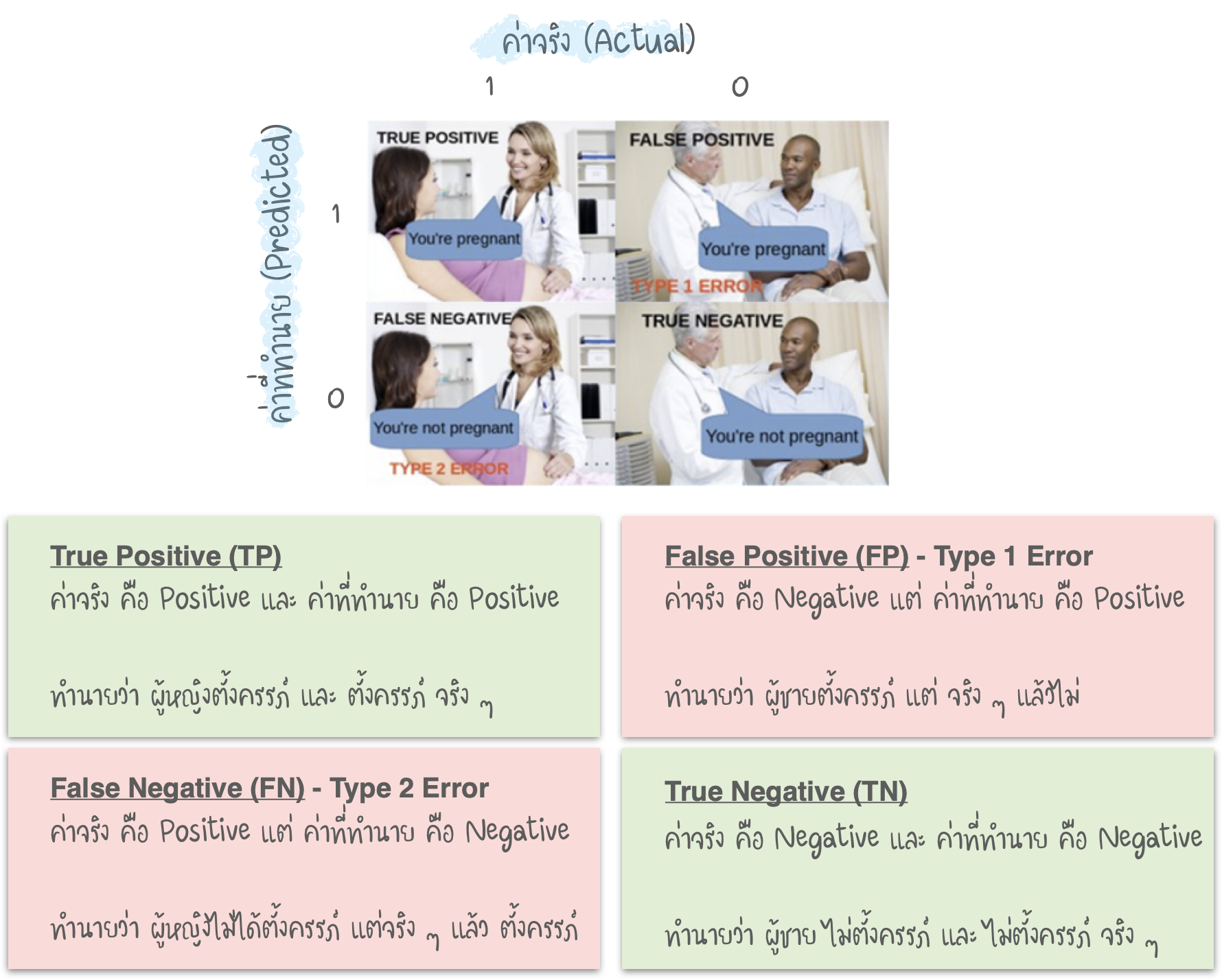
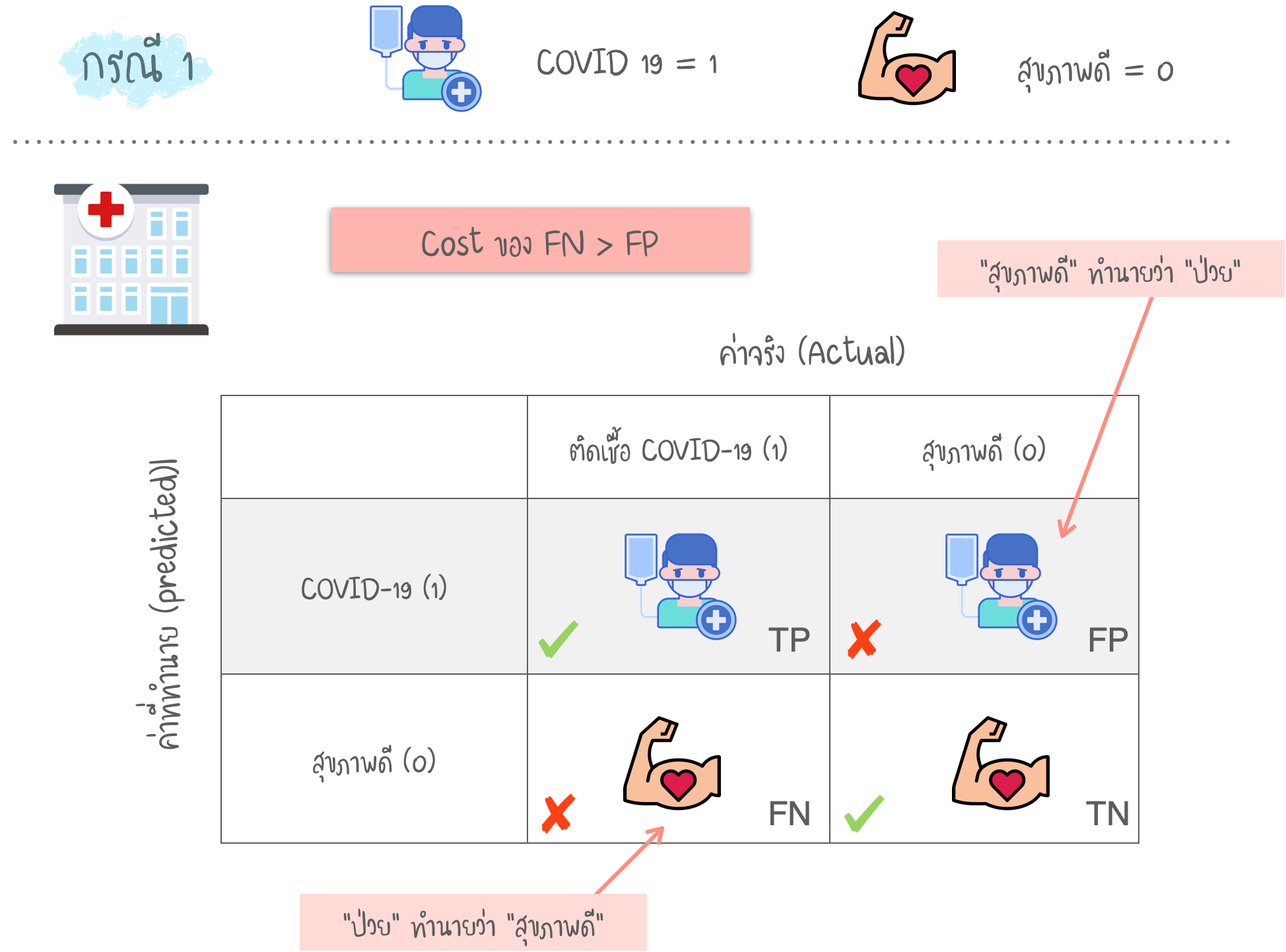
- TP : ค่าจริง เป็น Positive -> ค่าที่ ทำนาย เป็น Positive
- FN : ค่าจริง เป็น Positive -> ค่าที่ ทำนาย เป็น Negative
- TN : ค่าจริง เป็น Negative -> ค่าที่ ทำนาย เป็น Negative
- FP : ค่าจริง เป็น Negative -> ค่าที่ ทำนาย เป็น Positive
- Confusion Matrix สามารถวัด Recall, Precision, Accuracy และ AUC-ROC Curve
4 สมการของ Classification Metrics

Precision และ Recall
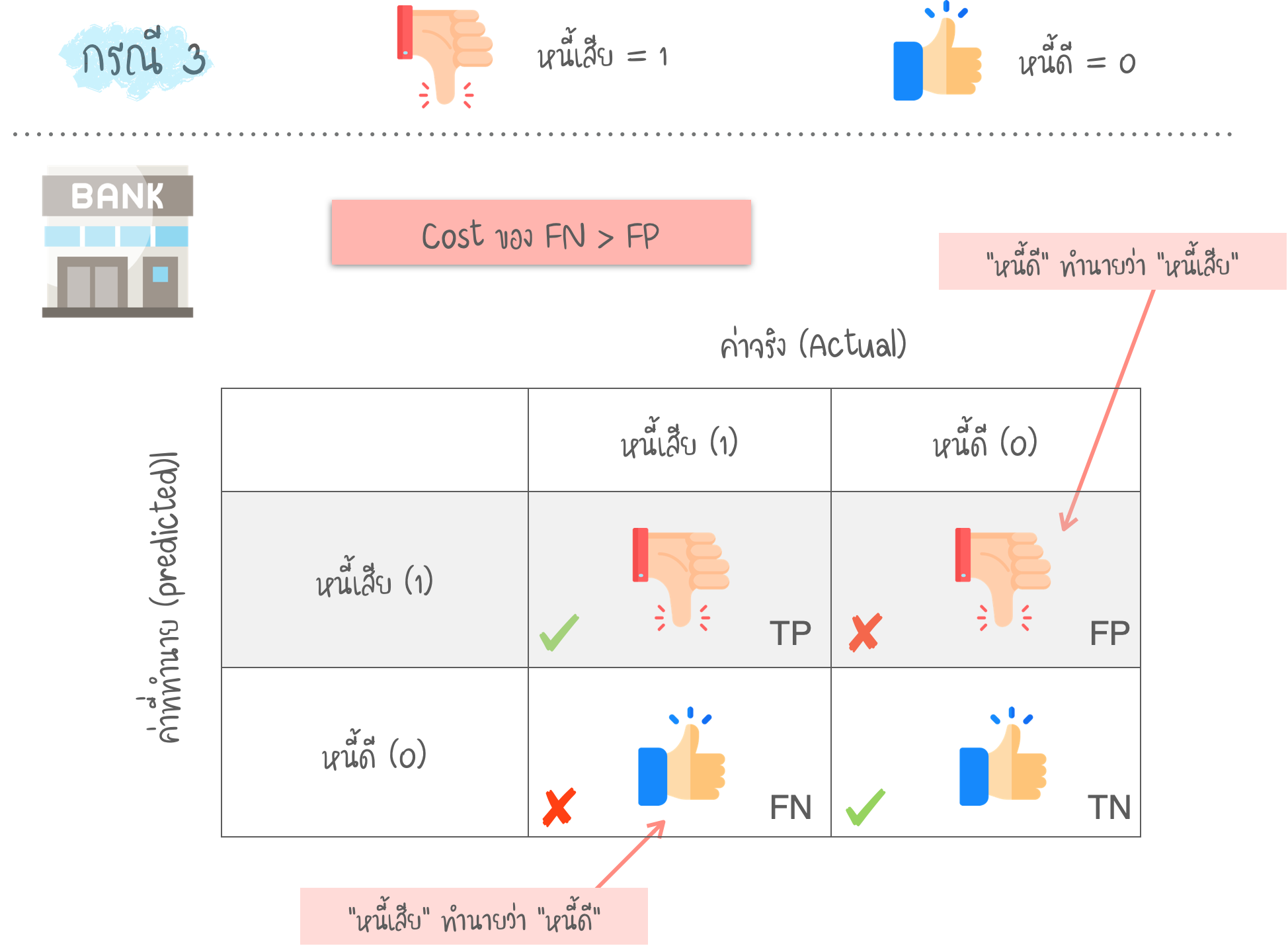
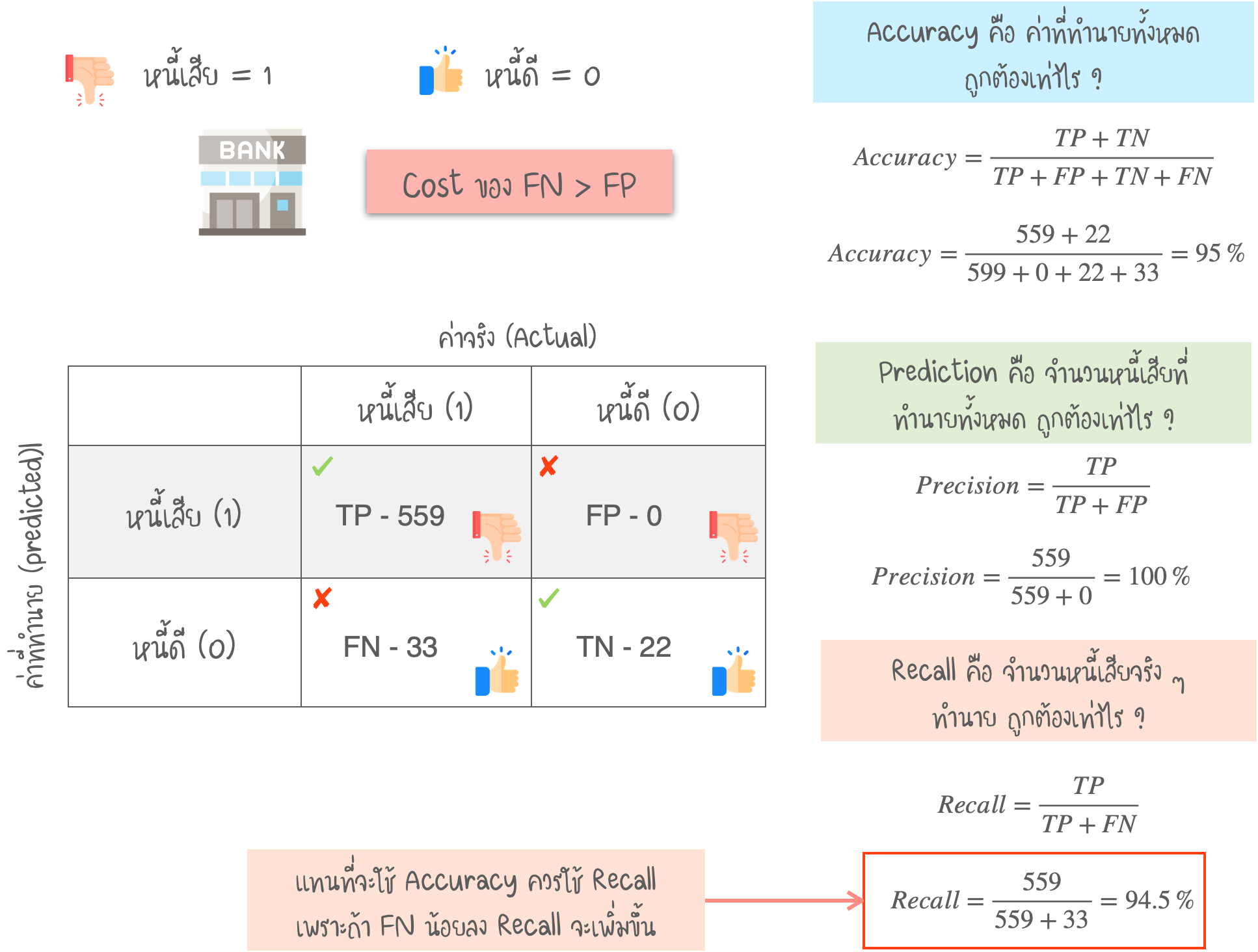
- Precision คือ อัตราส่วน ระหว่าง True Positive และค่าที่ทำนาย Positive ทั้งหมด (TP + FP) การที่ Precision ต่ำ หมายถึง “ค่า FP ที่สูง”
- Recall (หรือ Sensitivity) คือ อัตราส่วน ระหว่าง True Positive และค่า Positive ทั้งหมดในชุดข้อมูล (TP + FN) การที่ Recall ต่ำ หมายถึง “ค่า FN ที่สูง”
Precision และ Recall ไปสู่ F1 Score
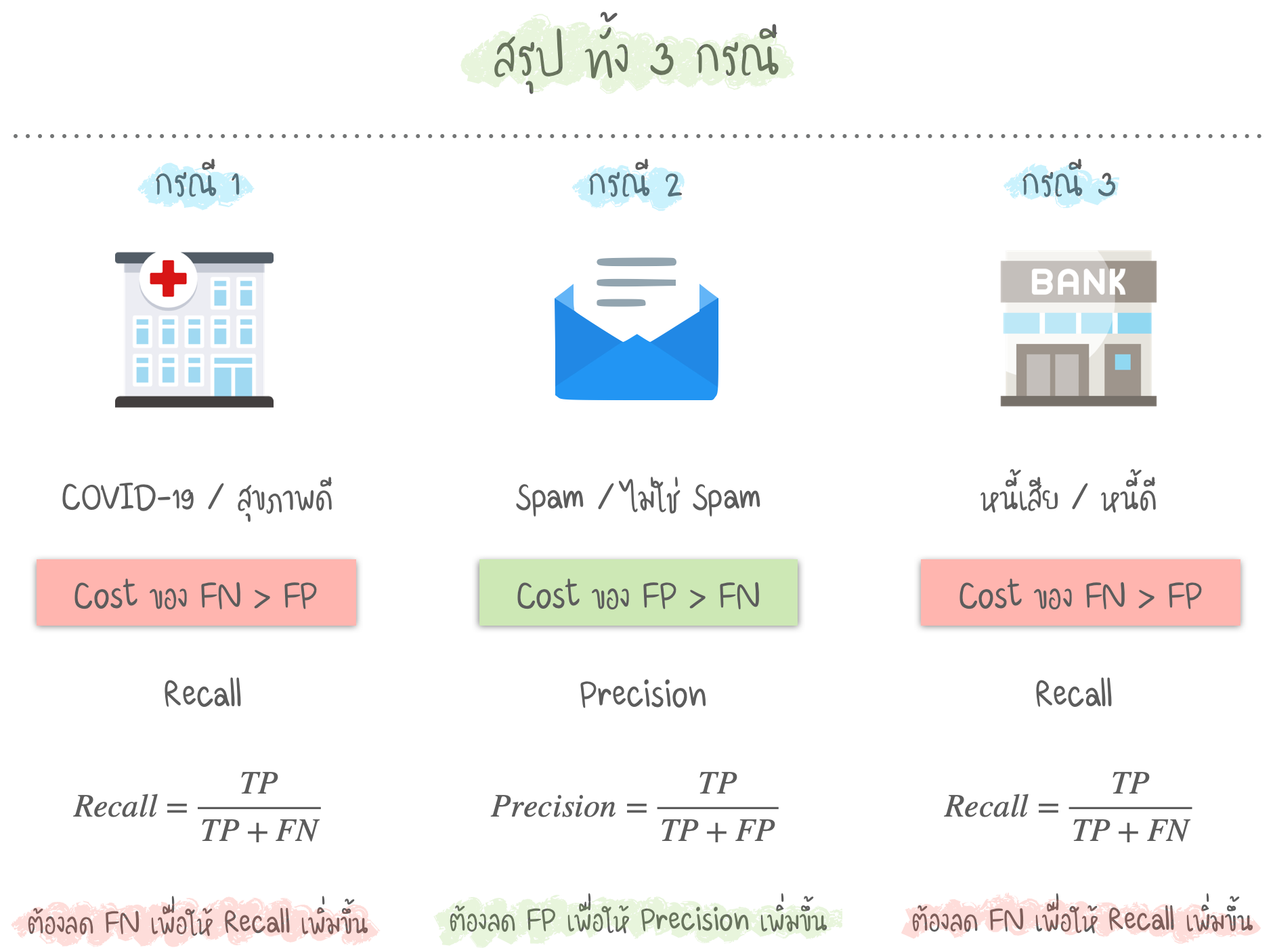
- ในตัวอย่างทั้ง 3 กรณี เราต้องการทำให้ค่า Precision หรือ Recall สูงที่สุด
- เช่น ในกรณี หนี้เสีย / หนี้ดี ต้องลดค่า FN เพื่อให้ค่า Recall เพิ่มขึ้น
- สำหรับ ในกรณีที่ต้องการ Optimize ทั้งสองค่า (Precision & Recall) สามารถเลือกใช้ค่า F1 Score

Decision Thresholds และ ROC Curve
- ROC (Receiver Operating Characteristic) คือ เทคนิคการ Visualization เพื่อแสดงประสิทธิภาพของ Classification Model
- เป็น Trade-off ระหว่าง TPR (True Positive Rate) และ FPR (False Positive Rate) ที่ค่า Probability threshold ที่ต่างกัน
- TPR คือ Recall และ FPR คือ ความน่าจะเป็นของ False Alarm
- ROC คือ การ Plot ระหว่าง TPR & FPR เป็นฟังก์ชันของ Model’s Threshold เพื่อจำแนกค่า Positive
- ให้ค่า c เป็นค่าคงที่ Decision Threshold พิจารณา ROC curve ด้านล่าง (ค่า default, c = 0.5)
- เมื่อ c = 0.2 ทั้ง TPR และ FPR เพิ่มขึ้น
- เมื่อ c = 0.8 ทั้ง TPR และ FPR จะลดลง
- เมื่อ c มีค่าลดลง TPR และ FPR จะเพิ่มขึ้น
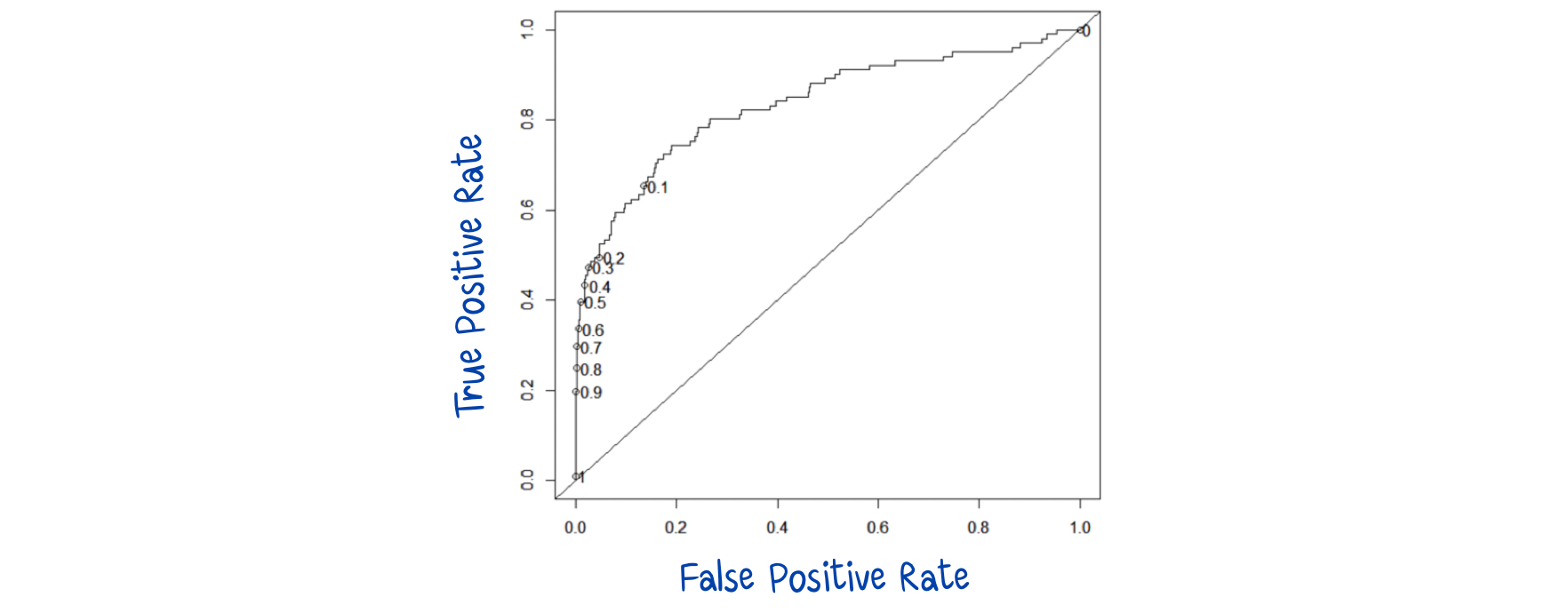
- เมื่อ c = 1 ทุกกรณีจะถูกทำนายเป็น Negative (TPR = FPR = 0) ในทางตรงกันข้าม เมื่อ c = 0 ทุกกรณีจะถูกทำนายเป็น Positive (TPR = FPR = 1)
- ประสิทธิภาพของ Model สามารถประเมิน โดยพื้นที่ใต้ ROC curve (AUC) โดยทั่วไป 0.9–1 = ดีเยี่ยม, 0.8-0.9 = ดี, 0.7-0.8 = พอใช้, 0.6-0.7 = แย่, 0.5-0.6 = แย่มาก
******
ข้อมูลอ้างอิง - https://www.kdnuggets.com/2020/04/performance-evaluation-metrics-classification.html