เปิดเผยความลับของ Bias และ Variance

ทำความเข้าใจระหว่าง Bias (อคติ) และ Variance (ความแปรปรวน)
ในการพัฒนา Machine Learning Models การทำให้ได้ผลการคาดการณ์ที่แม่นยำ ทั้งในขั้นตอนการพัฒนา (Development) และ การใช้งานจริง (Deployment) ถือเป็นเป้าหมายสำคัญ มี 2 แนวคิดพื้นฐาน เรียกว่า Bias (อคติ) และ Variance (ความแปรปรวน) หากเข้าใจความสัมพันธ์ระหว่าง 2 สิ่งนี้ จะสามารถสร้าง Model ที่มีประสิทธิภาพได้
Bias หมายถึง ข้อผิดพลาดที่เกิดจากสมมติฐานและข้อจำกัดของ Model เช่น Model ทำนายราคาบ้านที่ต่ำกว่าราคาจริงตลอดเวลา เนื่องจากไม่คำนึงถึงปัจจัยสำคัญอย่างเช่น ที่ตั้ง การประเมินต่ำตลอดเวลานี้ คือ Bias
Variance ในทางกลับกัน หากใช้ Model ที่ซับซ้อนมากอาจทำงานได้ดีในขั้นตอน Train (Development) แต่ทำงานได้ไม่ดีกับข้อมูลที่ไม่เคยเห็นมาก่อน (Unseen Data) ในขั้นตอนการใช้งานจริง (Deployment) แบบนี้ คือ Variance
Trade-off ระหว่าง Bias และ Variance เป็นหลักการพื้นฐานของ Machine Learning เมื่อเราเพิ่มความซับซ้อนของ Model ค่า Bias มักจะลดลง เนื่องจาก Model สามารถ Capture Patterns ที่ซับซ้อนมากขึ้นในข้อมูล อย่างไรก็ตาม ความซับซ้อนของ Model ที่เพิ่มขึ้นนี้ นำไปสู่ ค่า Variance ที่เพิ่มขึ้น ทำให้ Model นี้ Over-fitting กับข้อมูล Train
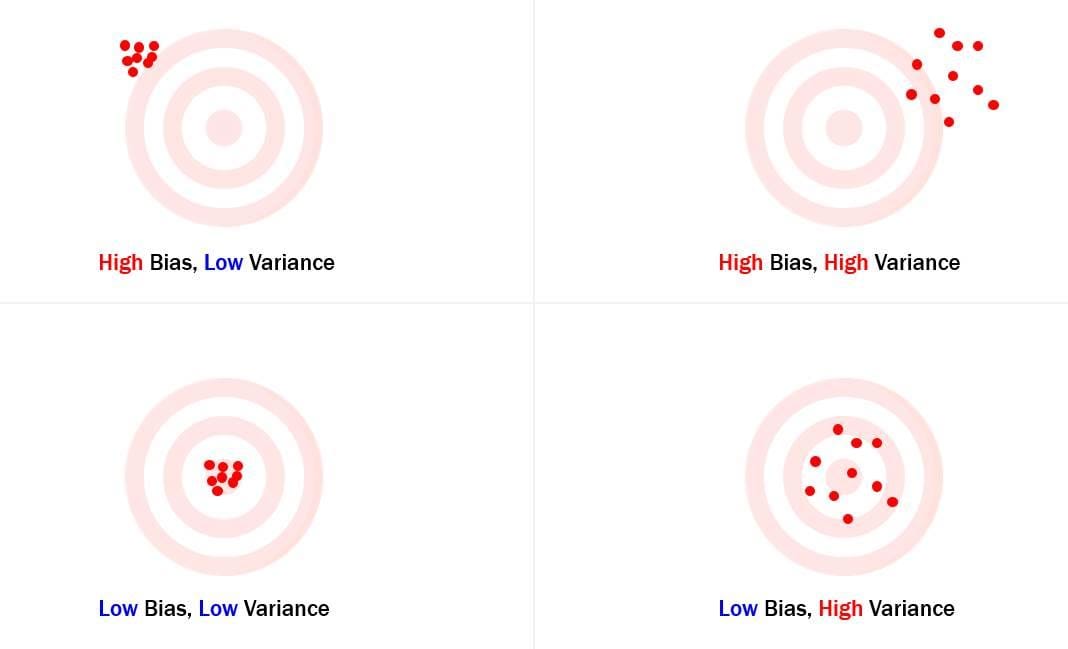
การเปรียบเทียบเพื่อแสดง Trade-off โดยให้จินตนาการถึงการปาลูกดอกใส่เป้า
- High Bias: ลูกดอกตกที่ตำแหน่งไกลจากจุดศูนย์กลางอย่างสม่ำเสมอ แสดงถึง Model ที่ไม่สามารถ Capture ความสัมพันธ์พื้นฐานในข้อมูล
- Low Bias: ลูกดอกกระจุกตัวอยู่รอบๆศูนย์กลาง แต่ไม่โดนจุดศูนย์กลาง บ่งบอกถึง Model ที่จับภาพแนวโน้มทั่วไปแต่ยังขาดความแม่นยำ
- High Variance: ลูกดอกกระจายไปทั่วกระดาน โดยบางลูกตกลงจุดศูนย์กลางโดยบังเอิญ สะท้อนถึง Model ที่ Over-fitting กับข้อมูลเฉพาะและไม่สามารถสรุปข้อมูลทั่วไปได้
- สถานการณ์ที่เหมาะสม: ลูกดอกกระจุกตัวอย่างแน่นหนาใกล้จุดศูนย์กลาง แสดงถึงโมเดลที่มี Bias และ Variance ต่ำ ได้ทั้งความแม่นยำและมีความสามารถในการสรุปข้อมูลทั่วไป
กาหาจุดสมดุล (Balance) ระหว่าง Bias และ Variance เป็นสิ่งสำคัญสำหรับการสร้าง Machine Learning Model สามารถใช้เทคนิคต่อไปนี้
- Regularization: เทคนิค เช่น L1 และ L2 จะ Punishment สำหรับ Model ที่ซับซ้อน ช่วยลด Over-fitting และลด Variance
- Data Augmentation: การเพิ่มจำนวนและความหลากหลายของข้อมูล Train สามารถช่วยให้ Model เรียนรู้จากสถานการณ์ที่กว้างขึ้นและลด Variance
- การเลือก Model: การเลือกความซับซ้อนของ Model ที่เหมาะสมกับปัญหาเป็นสิ่งสำคัญ Model ที่ง่ายกว่ามักจะมี Variance ที่ต่ำกว่า แต่ก็จะมี Bias ที่สูงด้วย ในขณะที่ การเลือกใช้ Model ที่ซับซ้อนกว่าจะให้ผลตรงกันข้าม
ความเข้าใจเรื่อง Bias และ Variance ทำให้เลือกใช้เทคนิคที่เหมาะสม นำไปสู่การ Trade-off และ สร้าง Model ที่มีประสิทธิภาพ ซึ่งสรุปข้อมูลในอนาคต (Unseen Data) ได้ดี แต่แท้จริงแล้ว เป้าหมายไม่ใช่การกำจัด Bias และ Variance โดยสิ้นเชิง แต่เพื่อค้นหา Balance และ ได้มาซึ่ง Optimal Model นำไปสู่การคาดการณ์ที่แม่นยำและเชื่อถือได้
หมายเหตุ - Blog นี้ เป็นการเขียนร่วมกันกับ Gemini โดยใช้ตัวอย่าง Prompts ดังนี้
Can you please explain about bias and variance trade-off?
Note - การใช้ Prompt เหมือนกัน ในแต่ละครั้ง อาจให้คำตอบที่แตกต่างกัน


